
Problem
The Executors tab in the Spark UI shows less memory than is actually available on the node:
AWS
- An m4.xlarge instance (16 GB ram, 4 core) for the driver node, shows 4.5 GB memory on the Executors tab.
- An m4.large instance (8 GB ram, 2 core) for the driver node, shows 710 MB memory on the Executors tab:
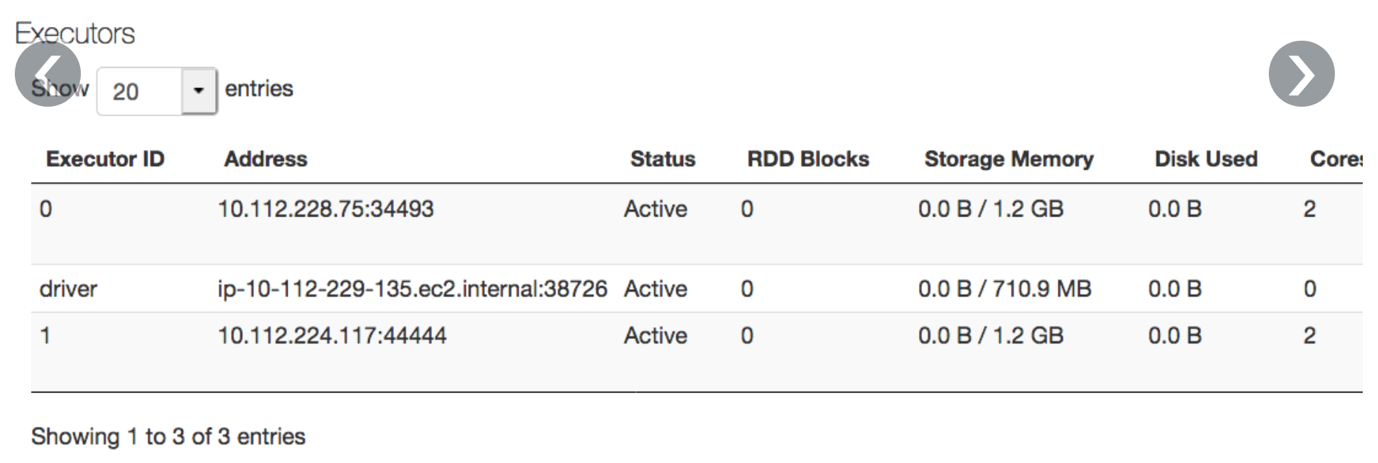
Azure
- An F8s instance (16 GB, 4 core) for the driver node, shows 4.5 GB of memory on the Executors tab.
- An F4s instance (8 GB, 4 core) for the driver node, shows 710 MB of memory on the Executors tab:
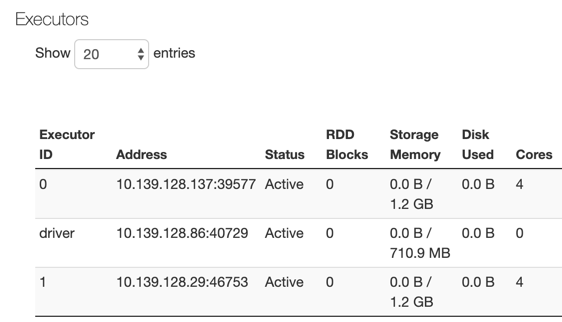
Cause
The total amount of memory shown is less than the memory on the cluster because some memory is occupied by the kernel and node-level services.
Solution
To calculate the available amount of memory, you can use the formula used for executor memory allocation (all_memory_size * 0.97 - 4800MB) * 0.8, where:
- 0.97 accounts for kernel overhead.
- 4800 MB accounts for internal node-level services (node daemon, log daemon, and so on).
- 0.8 is a heuristic to ensure the LXC container running the Spark process doesn’t crash due to out-of-memory errors.
Total available memory for storage on an instance is (8192MB * 0.97 - 4800MB) * 0.8 - 1024 = 1.2 GB. Because the parameter spark.memory.fraction is by default 0.6, approximately (1.2 * 0.6) = ~710 MB is available for storage.
You can change the spark.memory.fraction Spark configuration (AWS | Azure) to adjust this parameter. Calculate the available memory for a new parameter as follows:
- If you use an instance, which has 8192 MB memory, it has available memory 1.2 GB.
- If you specify a spark.memory.fraction of 0.8, the Executors tab in the Spark UI should show: (1.2 * 0.8) GB = ~960 MB.