Problem
You create a DataFrame using a complex dictionary and display it, such as in the following example.
result = [
{
"A": {'AA': 'aa', 'BB': {'AAA': 'aaa'}}
}
]
df = spark.createDataFrame(result)
df.display()
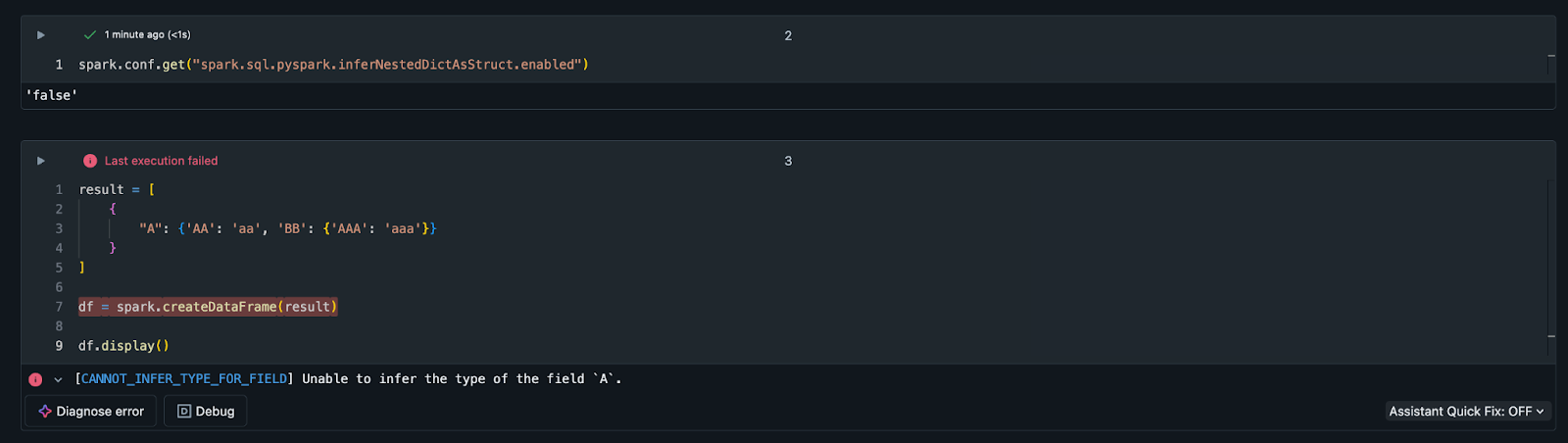
Upon executing, you receive the following error.
[CANNOT_INFER_TYPE_FOR_FIELD] Unable to infer the type of the field `A`.
The following screenshot shows the error in the UI.
Cause
By default, a dictionary’s values in its key-value pairs should have the same datatype.
In the example code, the first value ‘aa’ is a string, and the second value {'AAA': 'aaa'} is a further key-value pair. The difference causes the error.
Solution
To enable your code logic to accept different datatypes for different values in the dictionary, set the following Apache Spark configuration in the same notebook in a preceding cell.
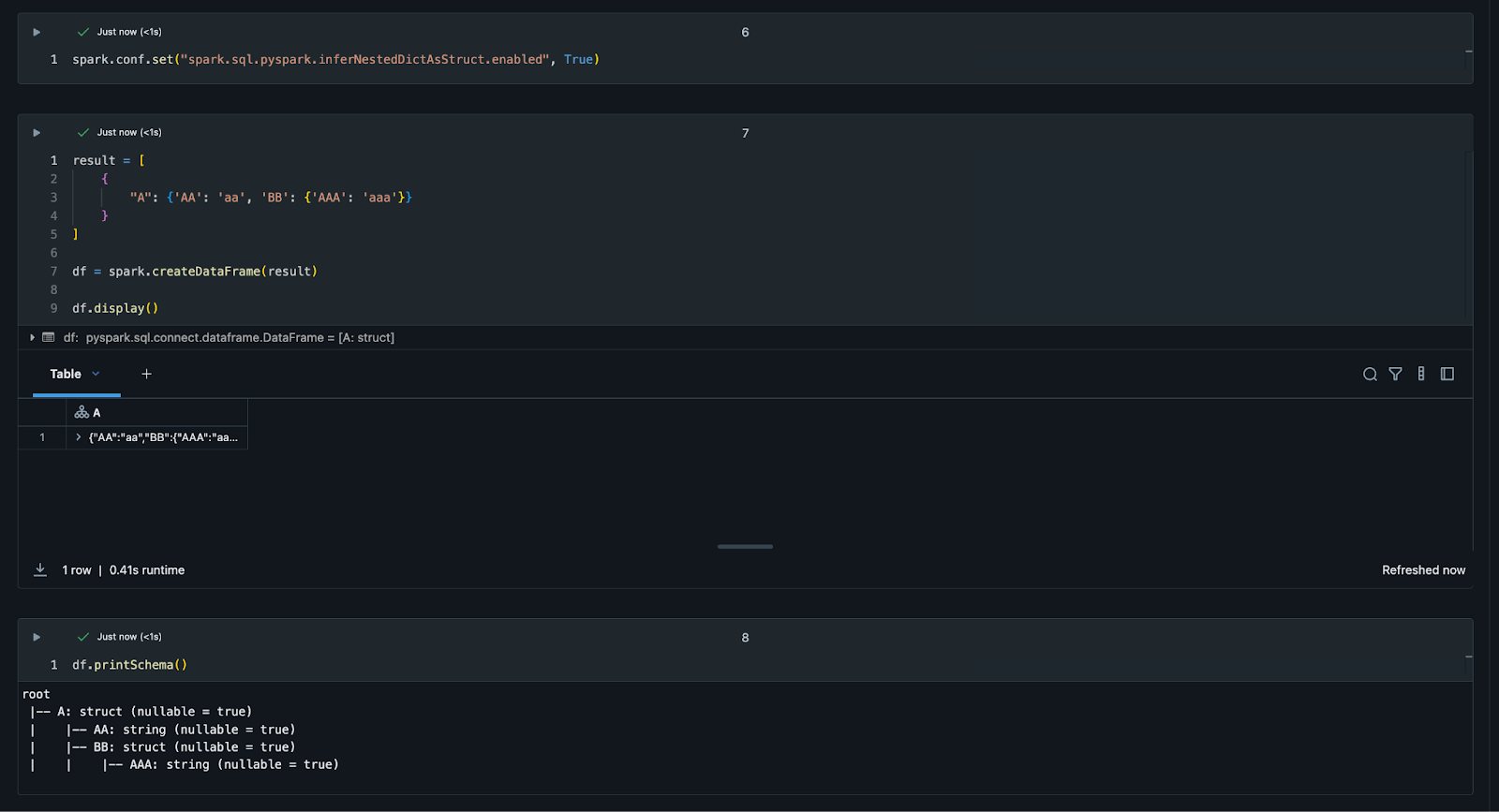
spark.conf.set("spark.sql.pyspark.inferNestedDictAsStruct.enabled", True)
The following screenshot shows a notebook setting this configuration in a cell before the DataFrame code, and then the original DataFrame code runs successfully. The schema allows AA to have a string value, while BB has a key-value pair value.