
Problem
You are trying to read ORC files from a directory when you get an error message:
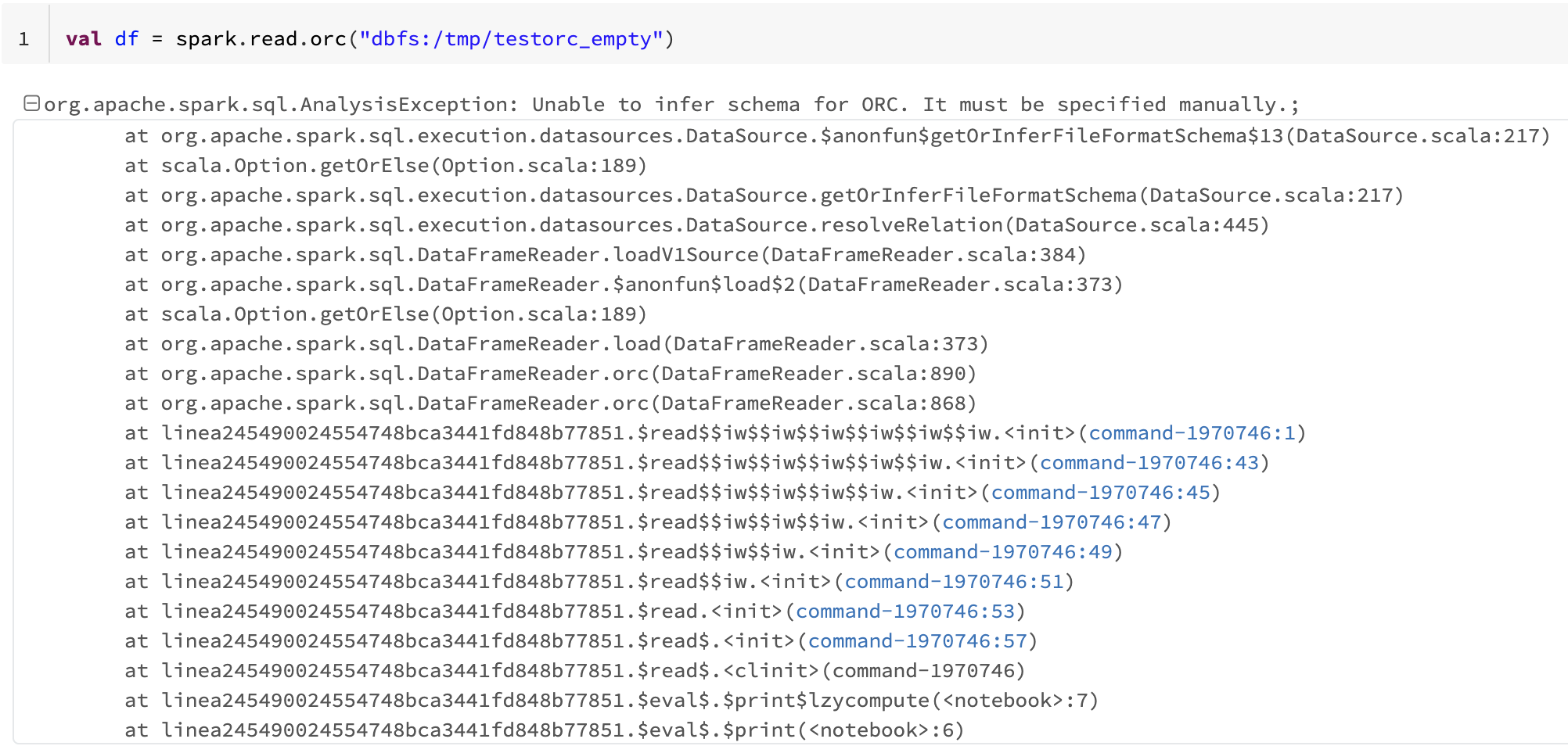
org.apache.spark.sql.AnalysisException: Unable to infer schema for ORC. It must be specified manually.
Cause
An Unable to infer the schema for ORC error occurs when the schema is not defined and Apache Spark cannot infer the schema due to:
- An empty directory.
- Using the base path instead of the complete path to the files when there are multiple subfolders containing ORC files.
Empty directory example
- Create an empty directory /tmp/testorc_empty.
%sh mkdir /dbfs/tmp/testorc_empty
- Attempt to read the directory.
val df = spark.read.orc("dbfs:/tmp/testorc_empty") - The read fails with an Unable to infer the schema for ORC error.
Base path example
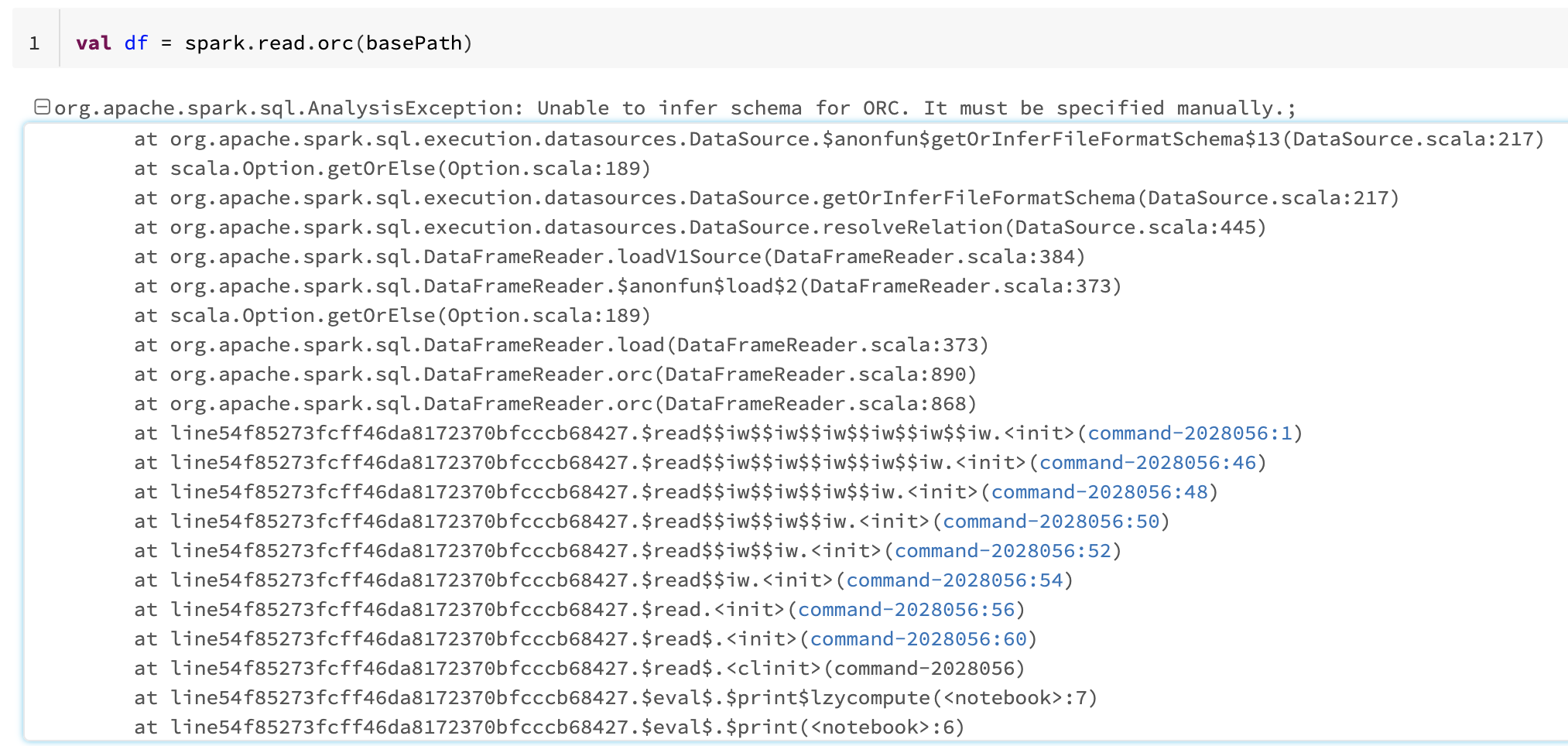
When only the base path is given (instead of the complete path) and there are multiple subfolders containing orc files, a read attempt returns the error: Unable to infer the schema for ORC.
- Create multiple folders under /tmp/testorc.
import org.apache.hadoop.fs.Path val basePath = "dbfs:/tmp/testorc" spark.range(1).toDF("a").write.orc(new Path(basePath, "first").toString) spark.range(1,2).toDF("a").write.orc(new Path(basePath, "second").toString) spark.range(2,3).toDF("a").write.orc(new Path(basePath, "third").toString) - Attempt to read the directory /tmp/testorc.
val df = spark.read.orc(basePath)
- The read fails with an Unable to infer scheme for ORC error.
Solution
Empty directory solution
- Create an empty directory /tmp/testorc_empty.
%sh mkdir /dbfs/tmp/testorc_empty
- Include the schema when you attempt to read the directory.
val df_schema = spark.read.schema("a int").orc("dbfs:/tmp/testorc_empty") - The read attempt does not return an error.

Base path solution
- Create multiple folders under /tmp/testorc.
import org.apache.hadoop.fs.Path val basePath = "dbfs:/tmp/testorc" spark.range(1).toDF("a").write.orc(new Path(basePath, "first1").toString) spark.range(1,2).toDF("a").write.orc(new Path(basePath, "second2").toString) spark.range(2,3).toDF("a").write.orc(new Path(basePath, "third3").toString) - Include the schema and a full path to one of the subfolders when you attempt to read the directory. In this example, we are using the path to the folder /third3/.
val dfWithSchema = spark.read.schema("a long").orc(basePath + "/third3/") - The read attempt does not return an error.

