
Problem
When working with Delta Live Tables (DLT), you notice all tables created within a for loop in your DLT pipeline load similar data columns. You observe that your tables have identical schemas, or the DLT graph of all the target tables points to a single source table.
Cause
When creating DLT tables within a for loop using the @dlt.table decorator, if the source table or file path is not passed as an argument to the function, the function will reference the last value in the for loop.
Context
The lazy execution model that pipelines use to evaluate Python code requires that your logic directly references individual values when the function decorated by @dlt.table() is invoked.
The for loop evaluates logic in serial order, but once planning is complete for the datasets, the pipeline runs logic in parallel.
Example of how the issue occurs
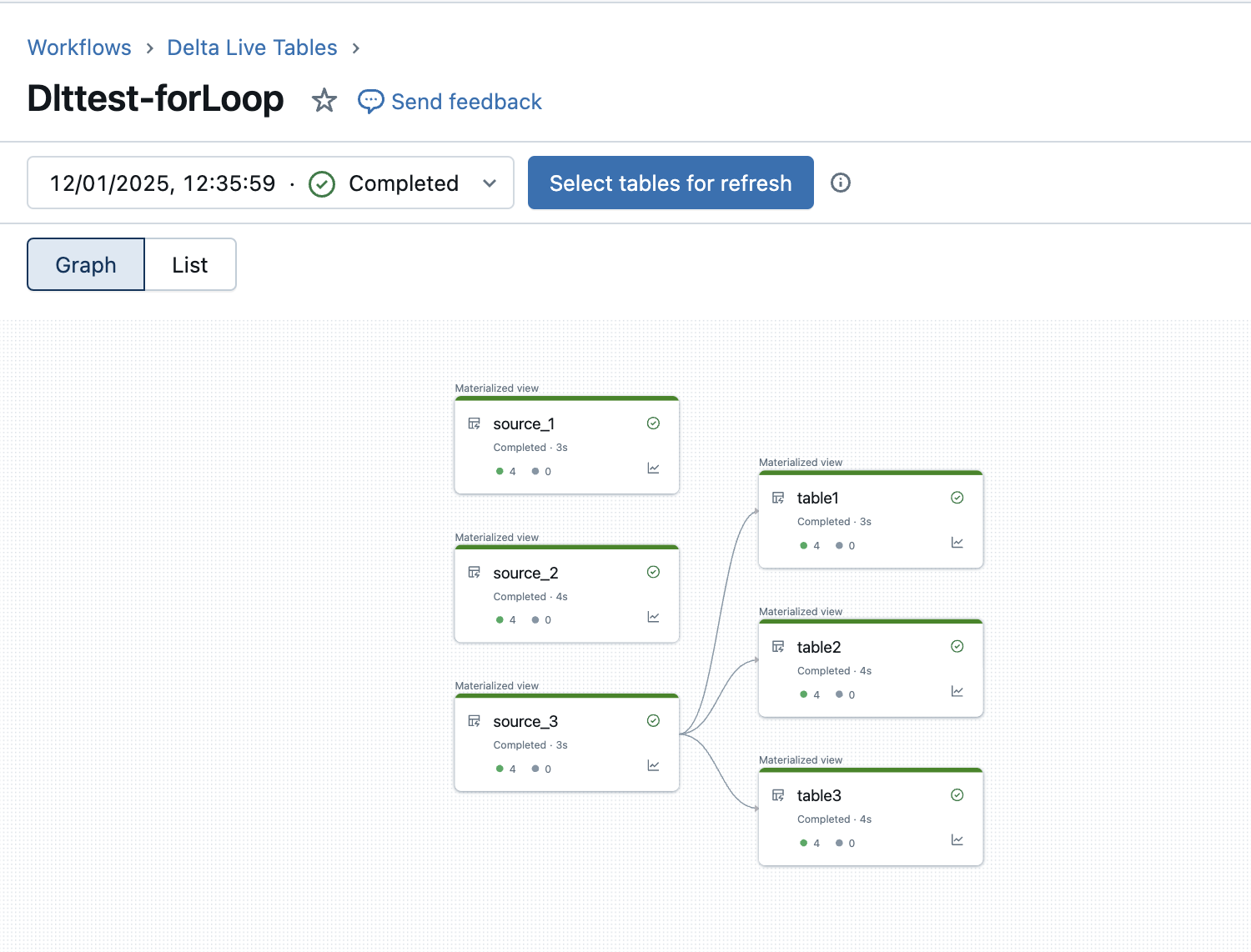
Three tables are created in both the bronze and silver layers by referring to the respective tables in the previous layer. The expected behavior is a one-to-one map of source to table.
source_1 → table1
source_2 → table2
source_3 → table3
The DLT notebook code used is the following.
import dlt
tables = ["source_1", "source_2", "source_3"]
for table_name in tables:
@dlt.table(name=table_name)
def create_table():
return spark.read.table("<catalog>.<schema>.<table>")
tables = ["table1", "table2", "table3"]
list={"table1":"source_1","table2":"source_2","table3":"source_3"}
for t_name in tables:
@dlt.table(name=t_name)
def create_table():
return spark.read.table(f"live.{list[t_name]}")
Once the DLT pipeline is executed, all the tables in the silver layer (table1, table2, and table3) are created by pointing to the same table source_3 from the previous (bronze) layer. The behavior that occurs is a one-to-three map of source to tables, instead of one-to-one.
source_1 →
source_2 →
source_3 → table1, table2, table3
The above example does not correctly reference the values. It creates tables with distinct names, but all tables load the data from the last value in the for loop. As a result, all tables will be created with the schema of the last source file/table processed in the loop.
Solution
1. In a notebook, modify your code to pass the source table as an argument to the create_table function instead.
import dlt
tables = ["source_1", "source_2", "source_3"]
for table_name in tables:
@dlt.table(name=table_name)
def create_table():
return spark.read.table("<your-catalog>.<your-schema>.<your-table>")
tables = ["table1", "table2", "table3"]
list={"table1":"source_1","table2":"source_2","table3":"source_3"}
for t_name in tables:
@dlt.table(name=t_name)
def create_table(source_table_name=f"{list[t_name]}"):
return spark.read.table(f"live.{source_table_name}")
2. Navigate to your DLT pipeline and execute it.
3. After the DLT pipeline is executed, verify the DLT graph to make sure the sources are mapping to tables one-to-one.