
Problem
You are running a job using notebooks that are stored in a remote Git repository (AWS | Azure | GCP). Databricks users with Can View permissions (who are not a workspace admin or owners of the job) cannot access or view the results of ephemeral jobs submitted via dbutils.notebook.run() from parent notebook.
Cause
When job visibility control (AWS | Azure | GCP) is enabled in the workspace, users can only see jobs permitted by their access control level. This works as expected with notebooks stored in the workspace. However, Databricks does not manage access control for your remote Git repo, so it does not know if there are any permission restrictions on notebooks stored in Git. The only Databricks user that definitely has permission to access notebooks in the remote Git repo is the job owner. As a result, other non-admin users are blocked from viewing, even if they have Can View permissions in Databricks.
Solution
You can work around this issue by configuring the job notebook source as your Databricks workspace and make the first task of your job fetch the latest changes from the remote Git repo.
This allows for scenarios where the job has to ensure it is using the latest version of a notebook stored in a shared, remote Git repo.
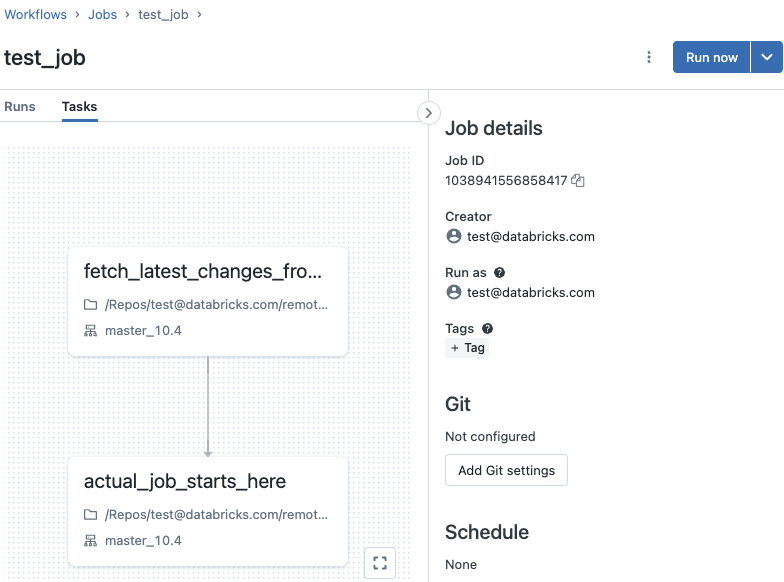
This image illustrates the two-part process. First, you fetch the latest changes to the notebook from the remote Git repo. Then, after the latest version of the notebook has been synced, you start running the notebook as part of the job.
Configure secret access
Create a Databricks personal access token
Follow the Personal access tokens for users (AWS | Azure | GCP) documentation to create a personal access token.
Create a secret scope
Follow the Create a Databricks-backed secret scope (AWS | Azure | GCP) documentation to create a secret scope.
Store your personal access token and your Databricks instance in the secret scope
Follow the Create a secret in a Databricks-backed scope (AWS | Azure | GCP) documentation to store the personal access token you created and your Databricks instance as new secrets within your secret scope.
Your Databricks instance is the hostname for your workspace, for example, xxxxx.cloud.databricks.com.
Use a script to sync the latest changes
This sample Python code pulls the latest revision from the remote Git repo and syncs it with the local notebook. This ensures the local notebook is up-to-date before processing the job.
You need to replace the following values in the script before running:
- <repo-id> - The name of the remote Git repo.
- <scope-name> - The name of your scope that holds the secrets.
- <secret-name-1> - The name of the secret that holds your Databricks instance.
- <secret-name-2> - The name of the secret that holds your personal access token.
%python
import requests
import json
databricks_instance = dbutils.secrets.get(scope = "<scope-name>", key = "<secret-name-1>")
token = dbutils.secrets.get(scope = "<scope-name>", key = "<secret-name-2>")
url = f"{databricks_instance}/api/2.0/repos/<repo-id>" # Use repos API to get repo id https://docs.databricks.com/dev-tools/api/latest/repos.html#operation/get-repos
payload = json.dumps({
"branch": "main" # use branch/tag. Refer https://docs.databricks.com/dev-tools/api/latest/repos.html#operation/update-repo
})
headers = {"Authorization": f"Bearer {token}", "Content-Type": "application/json"}
response = requests.request("PATCH", url, headers=headers, data=payload, timeout=60)
print(response.text)
if response.status_code != 200:
raise Exception(f"Failure during fetch operation. Response code: {response}")