
If you have a highly customized Databricks cluster, you may want to duplicate it and use it for other projects. When you clone a cluster, only the Apache Spark configuration and other cluster configuration information is copied. Installed libraries are not copies by default.
To copy the installed libraries, you can run a Python script after cloning the cluster.
Instructions
Identify source and target
The source cluster is the cluster you want to copy from.
The target cluster is the cluster you want to copy to.
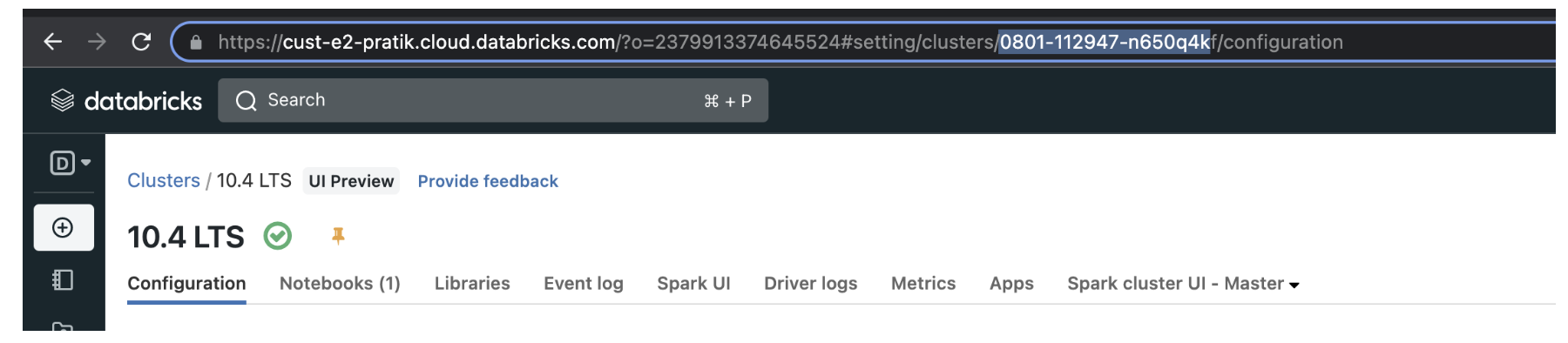
You can find the <source-cluster-id> and the <target-cluster-id> by selecting the cluster in the workspace, and then looking for the cluster ID in the URL.
https://<databricks-instance>/#/setting/clusters/<cluster-id>
In the following screenshot, the cluster ID is 0801-112947-n650q4k.
Create a Databricks personal access token
Follow the Personal access tokens for users (AWS | Azure | GCP) documentation to create a personal access token.
Create a secret scope
Follow the Create a Databricks-backed secret scope (AWS | Azure | GCP) documentation to create a secret scope.
Store your personal access token and your Databricks instance in the secret scope
Follow the Create a secret in a Databricks-backed scope (AWS | Azure | GCP) documentation to store the personal access token you created and your Databricks instance as new secrets within your secret scope.
Your Databricks instance is the hostname for your workspace, for example, xxxxx.cloud.databricks.com.
Use a Python script to clone the installed libraries
You can use this example Python script to copy the installed libraries from a source cluster to a target cluster.
You need to replace the following values in the script before running:
- <scope-name> - The name of your scope that holds the secrets.
- <secret-name-1> - The name of the secret that holds your Databricks instance.
- <secret-name-2> - The name of the secret that holds your personal access token.
- <source-cluster-id> - The cluster ID of the cluster you want to copy FROM.
- <target-cluster-id> - The cluster ID of the cluster you want to copy TO.
Copy the example script into a notebook that is attached to a running cluster in your workspace.
%python import requests import json import time from pyspark.sql.types import (StructField, StringType, StructType, IntegerType) API_URL = dbutils.secrets.get(scope = "<scope-name>", key = "<secret-name1>") # https://xxxxx.cloud.databricks.com/ TOKEN = dbutils.secrets.get(scope = "<scope-name>", key = "<secret-name2>") # Databricks PAT token source_cluster_id = "<source-cluster-id>" target_cluster_id = "<target-cluster-id>" source_cluster_api_url = API_URL+"/api/2.0/libraries/cluster-status?cluster_id=" + <source-cluster-id> response = requests.get(source_cluster_api_url,headers={'Authorization': "Bearer " + <TOKEN>}) libraries = [] for library_info in response.json()['library_statuses']: lib_type = library_info['library'] status = library_info['status'] libraries.append(lib_type) print("libraries from source cluster ("+source_cluster_id+") : "+str(libraries)+"\n") target_cluster_api_url = API_URL +"/api/2.0/libraries/install" target_lib_install_payload = json.dumps({'cluster_id': target_cluster_id, 'libraries': libraries}) print("Installing libraries in target cluster ("+source_cluster_id+") with payload: "+str(target_lib_install_payload)+"\n") response = requests.post(target_cluster_api_url, headers={'Authorization': "Bearer " + TOKEN}, data = target_lib_install_payload) if response.status_code ==200: print("Installation request is successful.Response code :"+str(response.status_code)) else: print("Installation failed.Response code :"+str(response.status_code))
Test target cluster
After the script finishes running, start the target cluster and verify that the libraries have been copied over.