
Problem
You are attempting to read a JSON file.
You know the file has data in it, but the Apache Spark JSON reader is returning a null value.
Example code
You can use this example code to reproduce the problem.
- Create a test JSON file in DBFS.
%python dbutils.fs.rm("dbfs:/tmp/json/parse_test.txt") dbutils.fs.put("dbfs:/tmp/json/parse_test.txt", """ {"data_flow":{"upstream":[{"$":{"source":"input"},"cloud_type":""},{"$":{"source":"File"},"cloud_type":{"azure":"cloud platform","aws":"cloud service"}}]}} """) - Read the JSON file.
%python jsontest = spark.read.option("inferSchema","true").json("dbfs:/tmp/json/parse_test.txt") display(jsontest) - The result is a null value.
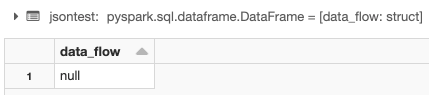
Cause
- In Spark 2.4 and below, the JSON parser allows empty strings. Only certain data types, such as IntegerType are treated as null when empty.
- In Spark 3.0 and above, the JSON parser does not allow empty strings. An exception is thrown for all data types, except BinaryType and StringType.
For more information, review the Spark SQL Migration Guide.
Example code
The example JSON shows the error because the data has two identical classification fields.
The first cloud_type entry is an empty string. The second cloud_type entry has data.
"cloud_type":""
"cloud_type":{"azure":"cloud platform","aws":"cloud service"}Because the JSON parser does not allow empty strings in Spark 3.0 and above, a null value is returned as output.
Solution
Set the Spark config (AWS | Azure | GCP) value spark.sql.legacy.json.allowEmptyString.enabled to True. This configures the Spark 3.0 JSON parser to allow empty strings.
You can set this configuration at the cluster level or the notebook level.
Example code
%python
spark.conf.set("spark.sql.legacy.json.allowEmptyString.enabled", True)
jsontest1 = spark.read.option("inferSchema","true").json("dbfs:/tmp/json/parse_test.txt")
display(jsontest1)