
Problem
The statistics functions covar_samp, kurtosis, skewness, std, stddev, stddev_samp, variance, and var_samp, return NaN when a divide by zero occurs during expression evaluation in Databricks Runtime 7.3 LTS. The same functions return null in Databricks Runtime 9.1 LTS and above, as well as Databricks SQL endpoints when a divide by zero occurs during expression evaluation.
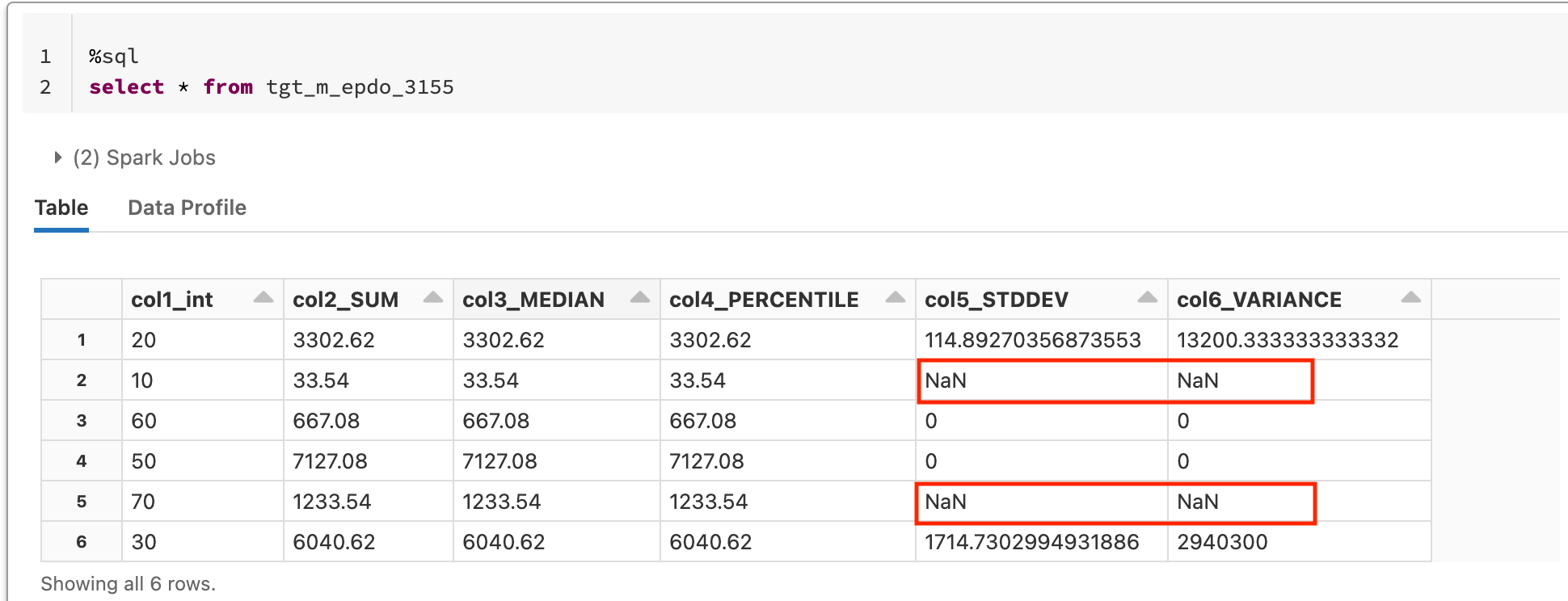
This example image shows sample results when running on Databricks Runtime 7.3 LTS. In cases where divide by zero occurs, the result is returned as NaN.
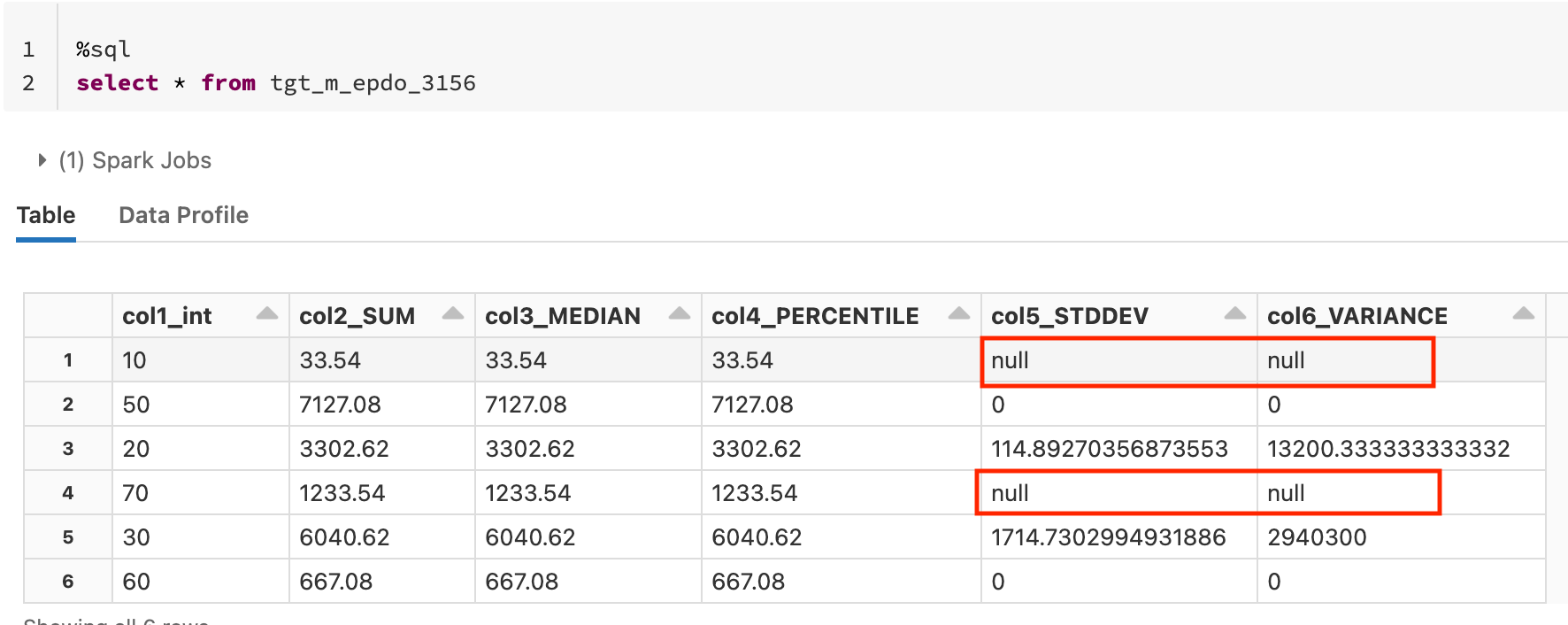
This example image shows sample results when running on Databricks Runtime 9.1 LTS. In cases where divide by zero occurs, the result is returned as null.
Cause
The change in behavior is due to an underlying change in Apache Spark.
In Spark 3.0 and below, the default behavior returns NaN when divided by zero occurs while evaluating a statistics function.
In Spark 3.1 this was changed to return null when divided by zero occurs while evaluating a statistics function.
For more information on the change, please review Spark PR [SPARK-13860].
Solution
Set spark.sql.legacy.statisticalAggregate to false in your Spark config (AWS | Azure | GCP) on clusters running Databricks Runtime 7.3 LTS.
This returns null instead of NaN when a divide by zero occurs while evaluating a statistics function.