LISTAGG is a function that aggregates a set of string elements into one string by concatenating the strings. An optional separator string can be provided which is inserted between contiguous input strings.
LISTAGG(<expression>, <separator>) WITHIN GROUP(ORDER BY …)
LISTAGG is supported in many databases and data warehouses. However, it is not natively supported in Apache Spark SQL or Databricks.
You can obtain similar functionality in Databricks by using collect_list (AWS | Azure | GCP) with concat_ws (AWS | Azure | GCP).
Instructions
Before using the commands, we first need to create sample data to process.
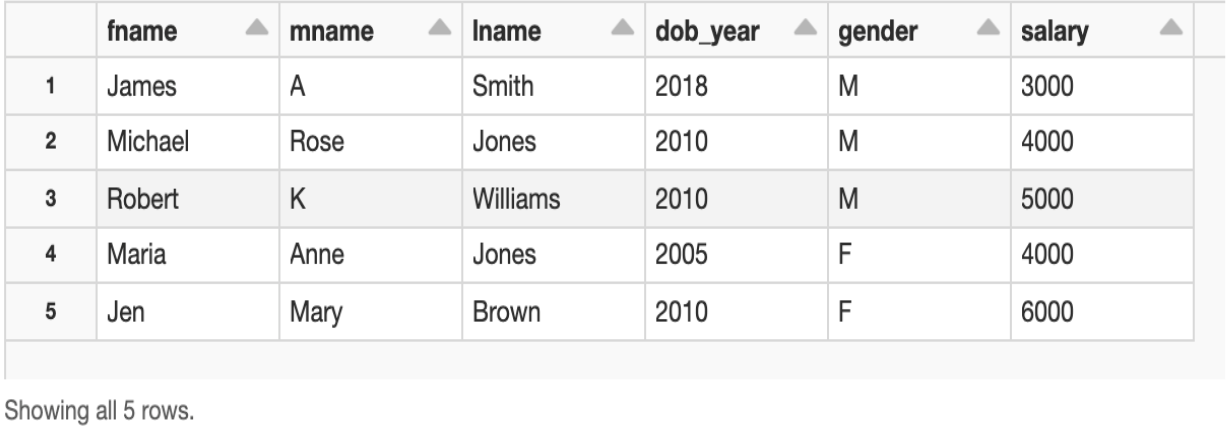
This sample code creates a table (named table1) that contains five lines of sample employee data.
%python
data = [["James","A","Smith","2018","M",3000],
["Michael","Rose","Jones","2010","M",4000],
["Robert","K","Williams","2010","M",5000],
["Maria","Anne","Jones","2005","F",4000],
["Jen","Mary","Brown","2010","F",6000]
]
df = spark.createDataFrame(data, ["fname","mname","lname","dob_year","gender","salary"])
df.createOrReplaceTempView("table1")
The sample table looks like this when viewed:
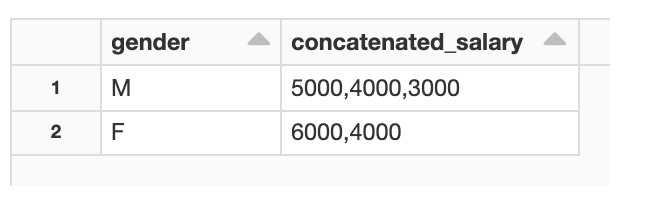
If you wanted to use LISTAGG to display a list of salaries by gender, you would use a query like this:
%sql SELECT gender, LISTAGG(salary, ',') WITHIN GROUP(ORDER BY salary) FROM table1 GROUP BY gender
The resulting table has two rows, with salary values separated by gender.
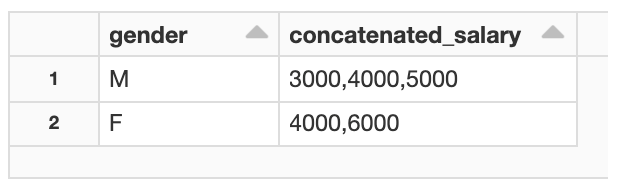
To replicate this functionality in Databricks, you need to use collect_list and concat_ws.
- collect_list creates a list of objects for the aggregated column. In this example, it gets the list of salary values for the aggregated gender column.
- concat_ws converts a list of salary objects to a single string value containing comma separated salaries.
This Spark SQL query returns the same result that you would get with LISTAGG on a different database.
%sql
SELECT gender,CONCAT_WS(',', COLLECT_LIST(salary)) as concatenated_salary
FROM table1
GROUP BY gender;
The resulting table has two rows, with salary values separated by gender.
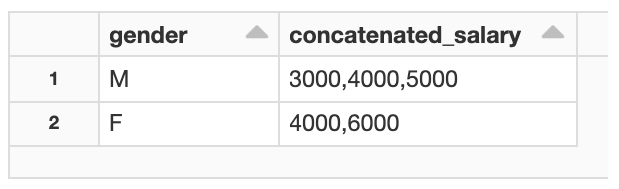
If you wanted to use LISTAGG to display the salary results in a descending order, you might write a query like this:
%sql SELECT gender, LISTAGG(salary, ',') WITHIN GROUP(ORDER BY salary DESC) FROM table1 GROUP BY gender
To do the same in Databricks, you would add sort_array to the previous Spark SQL example. collect_list and concat_ws do the job of LISTAGG, while sort_array is used to output the salary results in a descending order.
%sql
SELECT gender,CONCAT_WS(',', SORT_ARRAY(COLLECT_LIST(salary), false)) as concatenated_salary
FROM table1
GROUP BY gender;Both sets of sample code return the same output, with salary values separated by gender and displayed in descending order.