
Problem
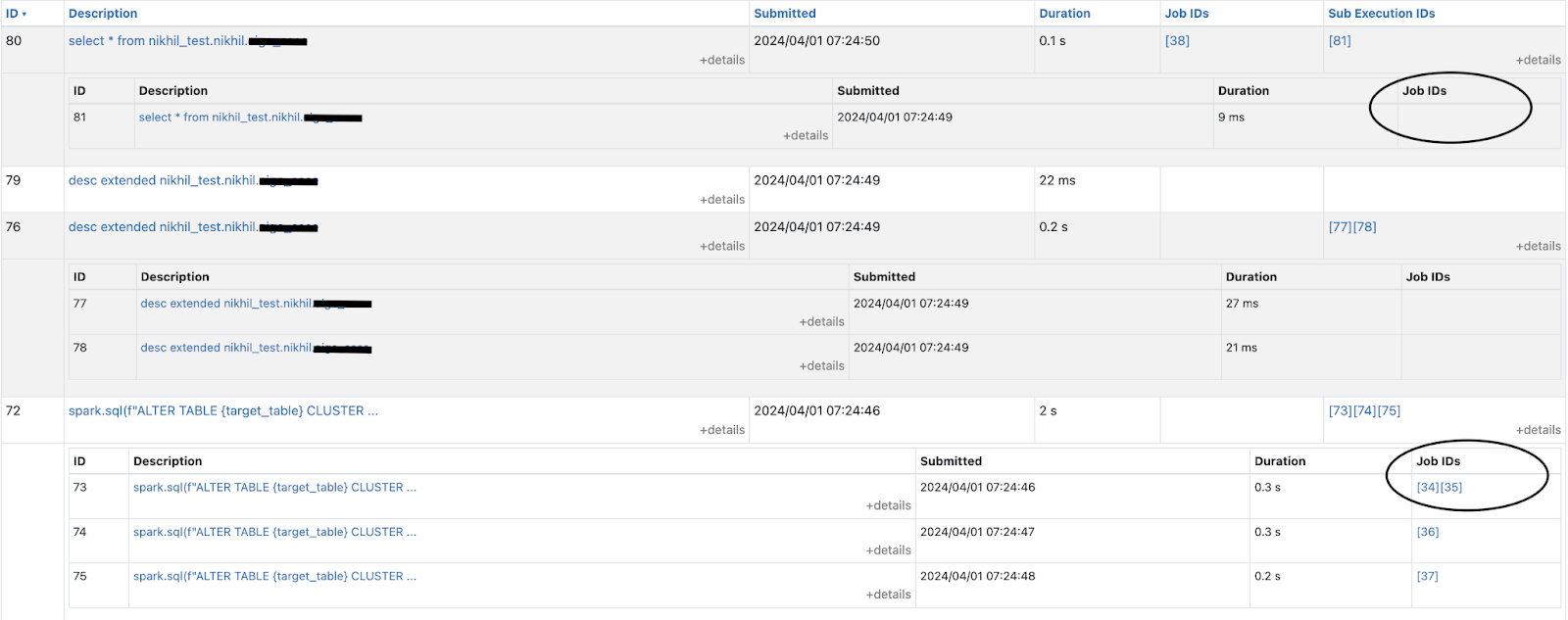
When you’re reviewing your Apache Spark UI to optimize query performance, you notice a Sub Execution ID column in addition to the query ID column in the SQL/DataFrame tab. You also notice that the Job ID column doesn’t consistently show values in the UI, as shown in the following image.
Cause
A Job ID is generated for a Sub Execution ID only when an action, such as collect(), count(), or saveAsTextFile() is triggered. If no such action is required (for example in certain transformations such as map(), filter(), or simple metadata fetching), Spark will not create a new Job ID, leaving Sub Execution IDs with no corresponding job.
Context
Sub Execution IDs in the Spark UI are identifiers for individual sub-parts of the queries executed in Spark. A query is divided into multiple Sub Execution IDs to enhance its execution speed. You can review the relationship between Job ID and Sub Execution Job IDs in the SQL/DataFrame tab.
Solution
To view all the Sub Execution IDs together in your Spark UI’s SQL/DataFrame tab:
- Click the Sub Execution IDs column, which opens in a new window.
- Click the Sub Execution IDs column again to sort the column and see all the IDs together.