Problem
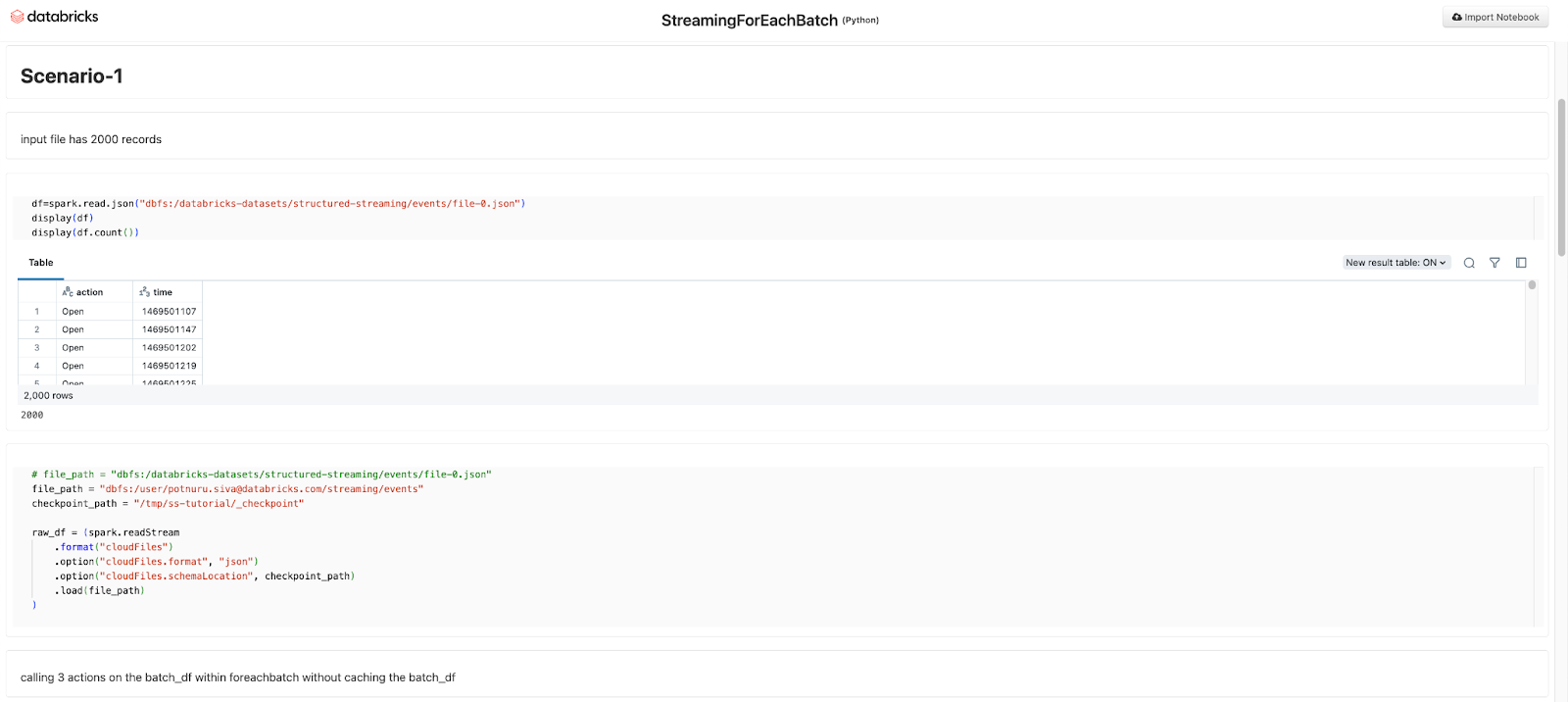
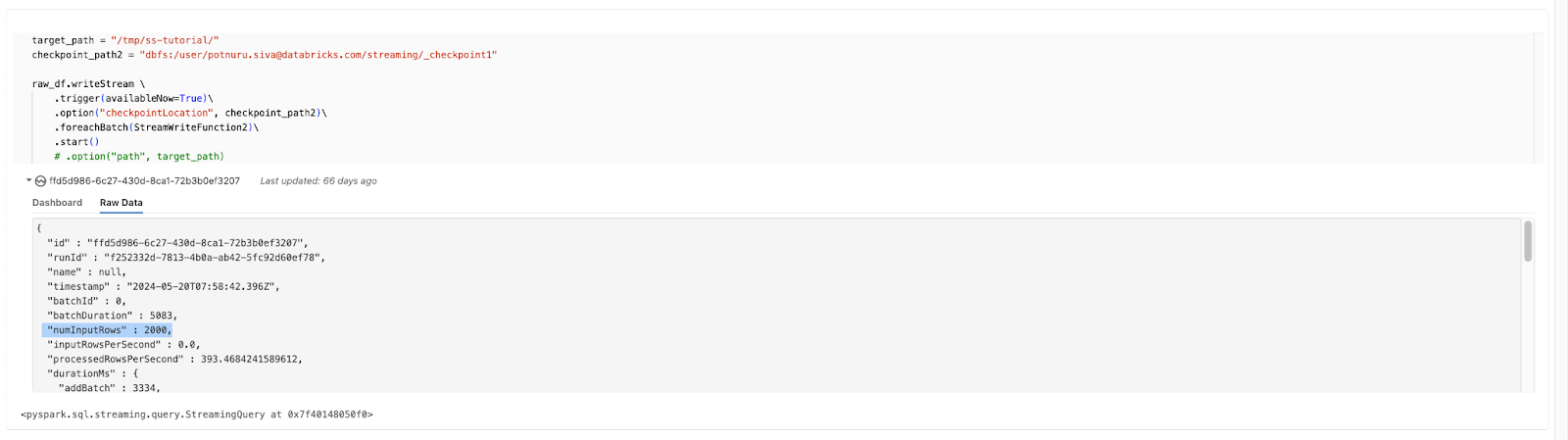
When observing the logs of Spark Streaming applications, you notice the metric numInputRows in the micro batch metrics or number of input records, event.progress.numInputRows, logged using the StreamingQueryListener does not match the expected count. This leads to confusion about the actual number of records being processed.
Cause
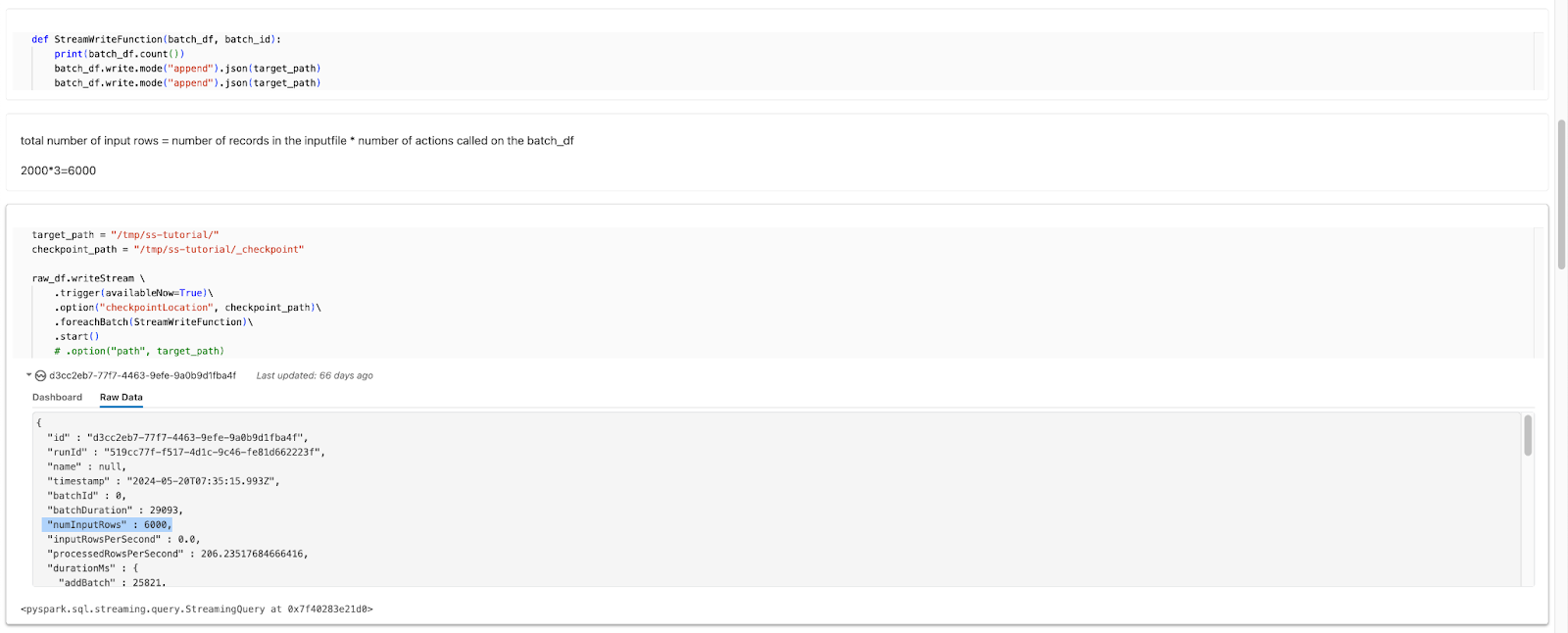
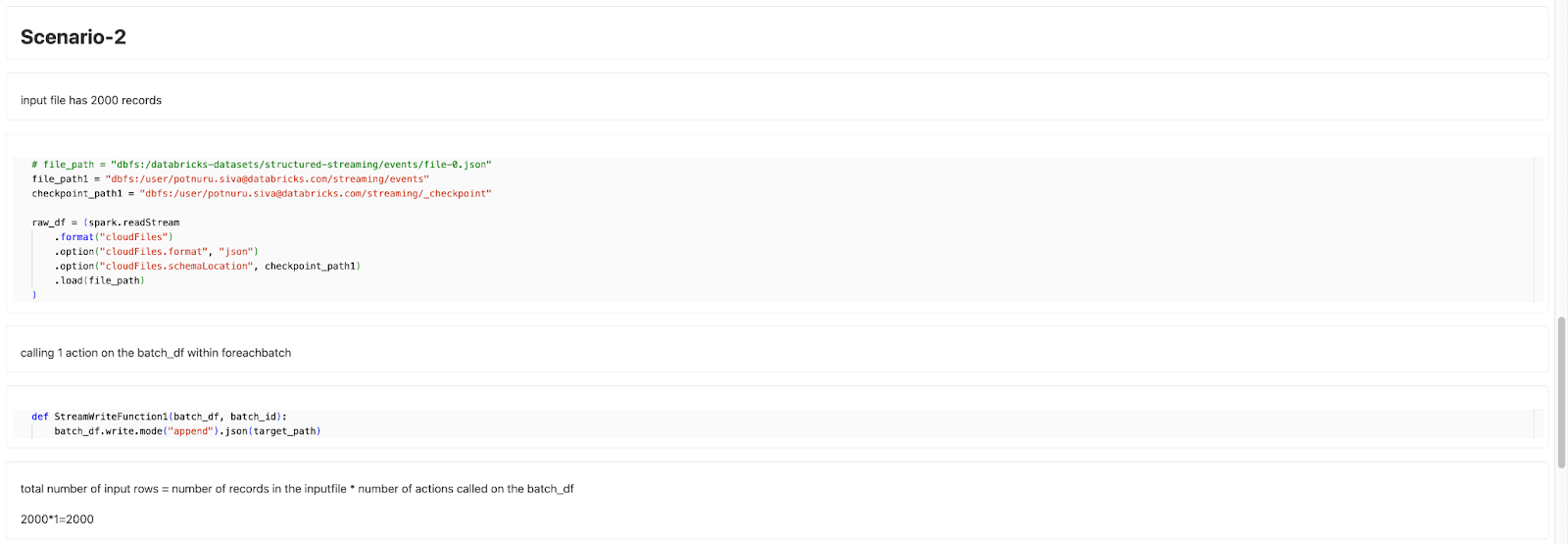
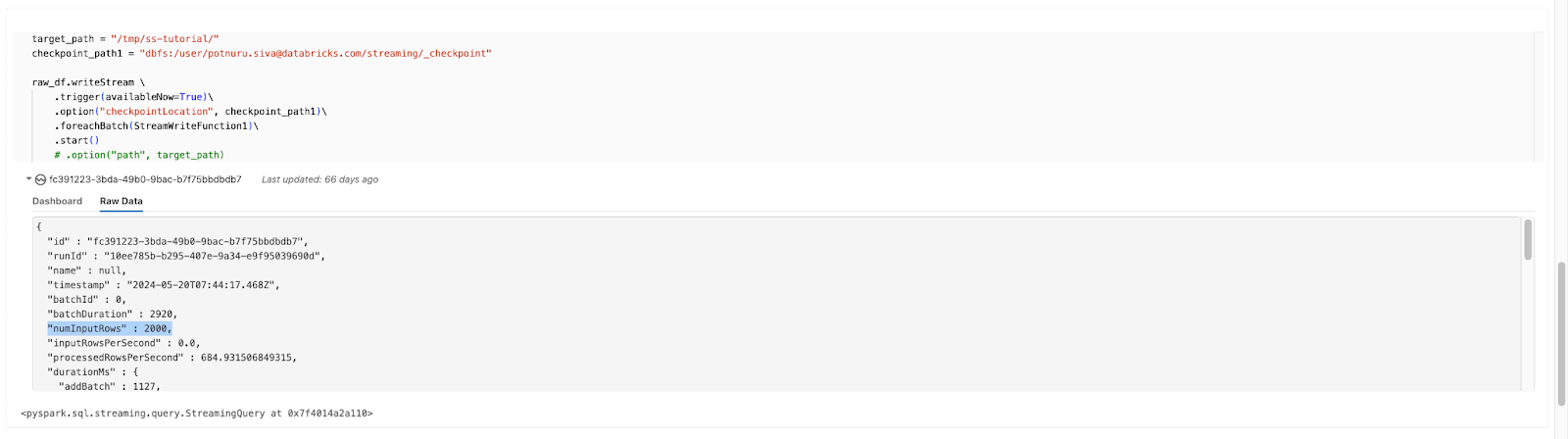
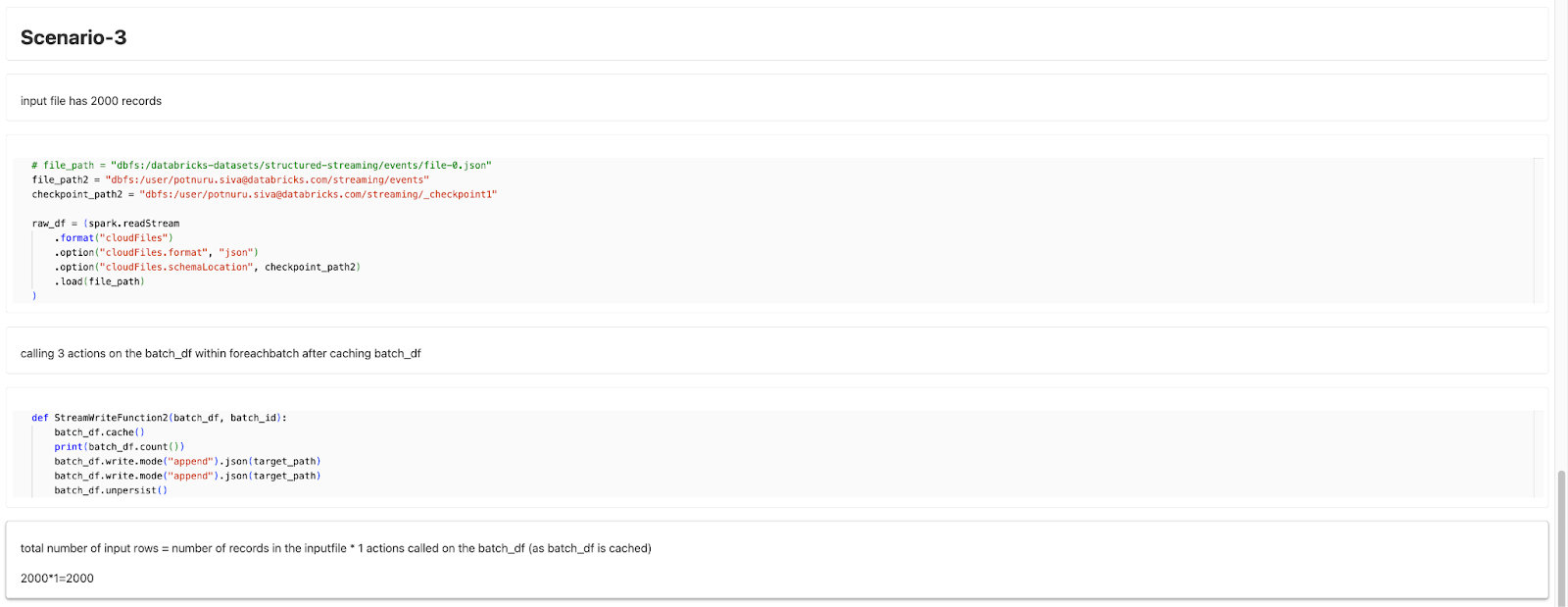
A discrepancy in the input record count happens when multiple actions are triggered on the same DataFrame within the foreachBatch function.
When an action is called more than once on the same stream, the numInputRows value counts the total number of records read for all actions in the code. If actions like df.count() are called multiple times, the same data is counted again, leading to an inflated record count in the logs. The inflated value appears in streaming micro batch metrics and queryListeners.
Solution
Optimize actions on the DataFrame within the foreachBatch function.
The recommended approach is to cache the DataFrame before performing any actions and unpersist it afterward to avoid resource leaks.
-
Cache the DataFrame using
df.cache()before performing any action. - Perform the necessary actions on the cached DataFrame.
-
Unpersist the DataFrame using
df.unpersist()after the actions are completed to free up resources.
For more information, please refer to the Apache Spark Class DataFrame documentation.