
This article describes how to access Azure Databricks with a Simba JDBC driver using Azure AD authentication.
This can be useful if you want to use an Azure AD user account to connect to Azure Databricks.
Create a service principal
Create a service principal in Azure AD. The service principal obtains an access token for the user.
- Open the Azure Portal.
- Open the Azure Active Directory service.
- Click App registrations in the left menu.
- Click New registration.
- Complete the form and click Register.
Your service principal has been successfully created.
Configure service principal permissions
- Open the service principal you created.
- Click API permissions in the left menu.
- Click Add a permission.
- Click Azure Rights Management Services.
- Click Delegated permissions.
- Select user_impersonation.
- Click Add permissions.
- The user_impersonation permission is now assigned to your service principal.

Update service principal manifest
- Click Manifest in the left menu.
- Look for the line containing the "allowPublicClient" property.
- Set the value to true.
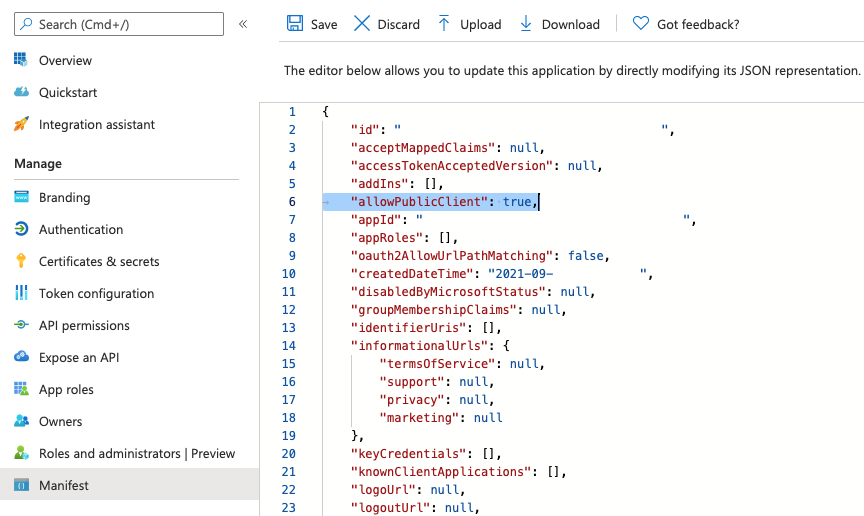
- Click Save.
Download and configure the JDBC driver
- Download the Databricks JDBC Driver.
- Configure the JDBC driver as detailed in the documentation.
Obtain the Azure AD token
Use the sample code to obtain the Azure AD token for the user.
Replace the variables with values that are appropriate for your account.
%python
from adal import AuthenticationContext
authority_host_url = "https://login.microsoftonline.com/""
# Application ID of Azure Databricks
azure_databricks_resource_id = "2ff814a6-3304-4ab8-85cb-cd0e6f879c1d"
# Required user input
user_parameters = {
"tenant" : "<tenantId>",
"client_id" : "<clientId>",
"username" : "<user@domain.com>",
"password" : <password>
}
# configure AuthenticationContext
# authority URL and tenant ID are used
authority_url = authority_host_url + user_parameters['tenant']
context = AuthenticationContext(authority_url)
# API call to get the token
token_response = context.acquire_token_with_username_password(
azure_databricks_resource_id,
user_parameters['username'],
user_parameters['password'],
user_parameters['client_id']
)
access_token = token_response['accessToken']
refresh_token = token_response['refreshToken']Pass the Azure AD token to the JDBC driver
Now that you have the user’s Azure AD token, you can pass it to the JDBC driver using Auth_AccessToken in the JDBC URL as detailed in the Building the connection URL for the Databricks driver documentation.
This sample code demonstrates how to pass the Azure AD token.
%python
# Install jaydebeapi pypi module (used for demo)
import jaydebeapi
import pandas as pd
import os os.environ["CLASSPATH"] = "<path to downloaded Simba Spark JDBC/ODBC driver>"
# JDBC connection string
url="jdbc:spark://adb-111111111111xxxxx.xx.azuredatabricks.net:443/default;transportMode=http;ssl=1;httpPath=sql/protocolv1/o/<workspaceId>/<clusterId>;AuthMech=11;Auth_Flow=0;Auth_AccessToken={0}".format(access_token)
try:
conn=jaydebeapi.connect("com.simba.spark.jdbc.Driver", url)
cursor = conn.cursor()
# Execute SQL query
sql="select * from <tablename>"
cursor.execute(sql)
results = cursor.fetchall()
column_names = [x[0] for x in cursor.description]
pdf = pd.DataFrame(results, columns=column_names)
print(pdf.head())
# Uncomment the following two lines if this code is running in the Databricks Connect IDE or within a workspace notebook.
# df = spark.createDataFrame(pdf)
# df.show()
finally:
if cursor is not None:
cursor.close()