
By default, the amount of memory available for each executor is allocated within the Java Virtual Machine (JVM) memory heap. This is controlled by the spark.executor.memory property.
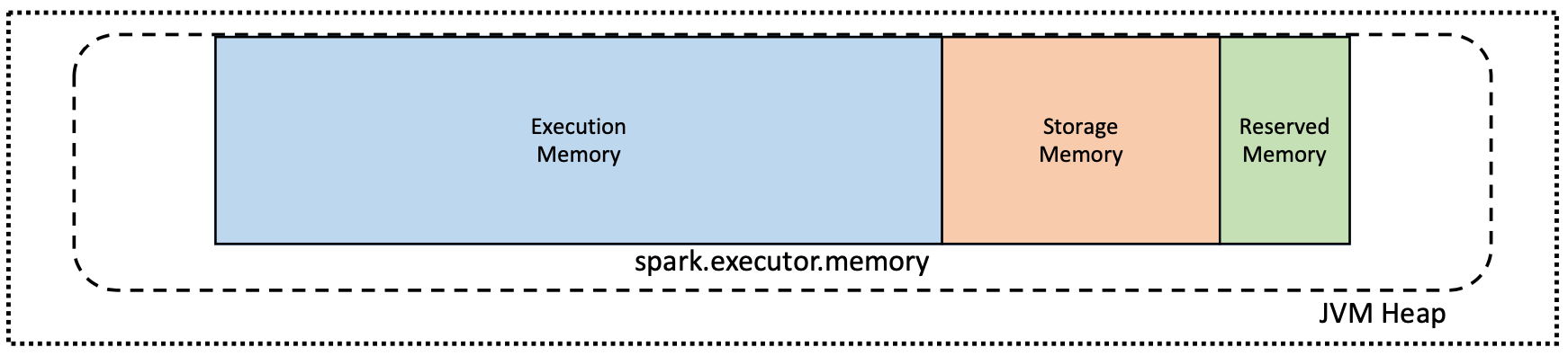
However, some unexpected behaviors were observed on instances with a large amount of memory allocated. As JVMs scale up in memory size, issues with the garbage collector become apparent. These issues can be resolved by limiting the amount of memory under garbage collector management.
Selected Databricks cluster types enable the off-heap mode, which limits the amount of memory under garbage collector management. This is why certain Spark clusters have the spark.executor.memory value set to a fraction of the overall cluster memory.
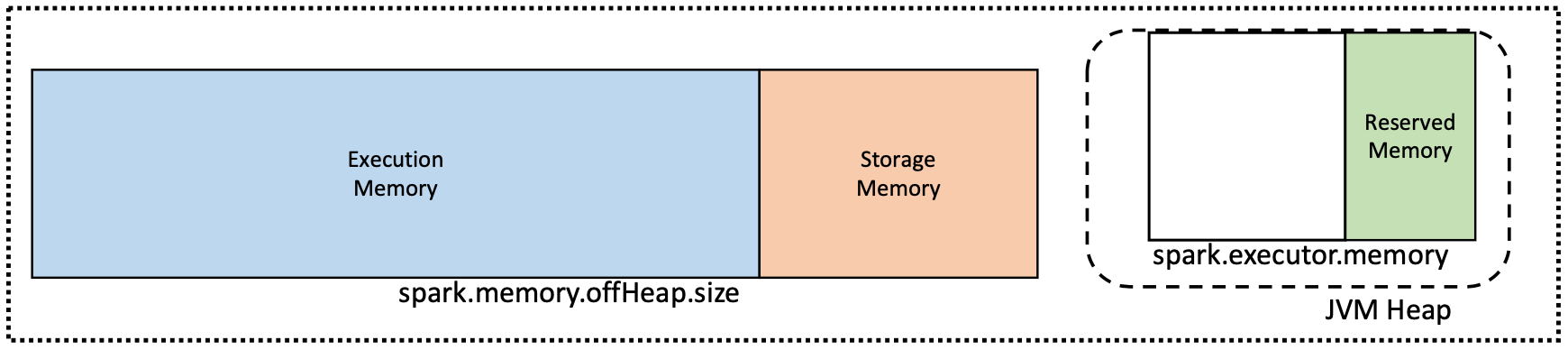
The off-heap mode is controlled by the properties spark.memory.offHeap.enabled and spark.memory.offHeap.size which are available in Spark 1.6.0 and above.
AWS
The following Databricks cluster types enable the off-heap memory policy:
- c5d.18xlarge
- c5d.9xlarge
- i3.16xlarge
- i3en.12xlarge
- i3en.24xlarge
- i3en.2xlarge
- i3en.3xlarge
- i3en.6xlarge
- i3en.large
- i3en.xlarge
- m4.16xlarge
- m5.24xlarge
- m5a.12xlarge
- m5a.16xlarge
- m5a.24xlarge
- m5a.8xlarge
- m5d.12xlarge
- m5d.24xlarge
- m5d.4xlarge
- r4.16xlarge
- r5.12xlarge
- r5.16xlarge
- r5.24xlarge
- r5.2xlarge
- r5.4xlarge
- r5.8xlarge
- r5a.12xlarge
- r5a.16xlarge
- r5a.24xlarge
- r5a.2xlarge
- r5a.4xlarge
- r5a.8xlarge
- r5d.12xlarge
- r5d.24xlarge
- r5d.2xlarge
- r5d.4xlarge
- z1d.2xlarge
- z1d.3xlarge
- z1d.6xlarge
- z1d.6xlarge
Azure
The following Azure Databricks cluster types enable the off-heap memory policy:
- Standard_L8s_v2
- Standard_L16s_v2
- Standard_L32s_v2
- Standard_L64s_v2
- Standard_L80s_v2