
The cost of a DBFS S3 bucket is primarily driven by the number of API calls, and secondarily by the cost of storage. You can use the AWS CloudTrail logs to create a table, count the number of API calls, and thereby calculate the exact cost of the API requests.
- Obtain the following information. You may need to contact your AWS Administrator to get it.
- API call cost for calls involving List, Put, Copy, or Post (the example script uses the price per thousand calls: 0.005/1000)
- API call cost for calls involving Head, Get, or Select (below, 0.0004/1000)
- Account ID for the Databricks control plane account (below, 414351767826)
- Copy the CloudTrail logs to an S3 bucket and use the following Apache Spark code to read the logs and create a table:
%python spark.read.json("s3://dbc-root-cloudwatch/*/*/*/*/*/*/*").createOrReplaceTempView("f_cloudwatch") - Substitute the accountIDand the API call costs into the following query. This query takes the CloudTrail results collected during a specific time interval, counts the number of API calls being made from the Databricks control plane account, and calculates the cost.
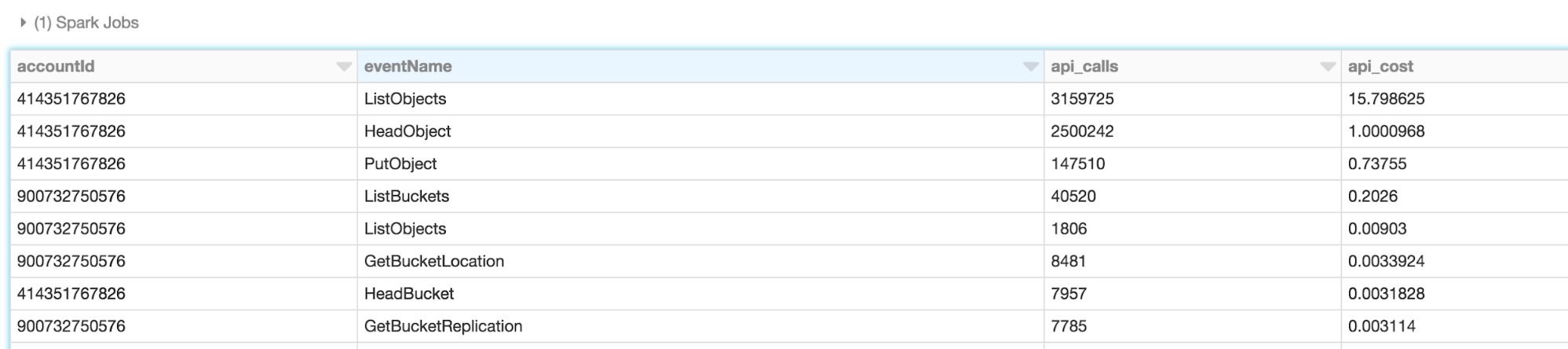
%sql select Records.userIdentity.accountId, Records.eventName, count(*) as api_calls, (case when Records.eventName like 'List%' or Records.eventName like 'Put%' or Records.eventName like 'Copy%' or Records.eventName like 'Post%' then 0.005/1000 when Records.eventName like 'Head%' or Records.eventName like 'Get%' or Records.eventName like 'Select%' then 0.0004/1000 else 0 end) * count(*) as api_cost from (select explode(Records) as Records from f_cloudwatch where Records is not null) -- where Records.userIdentity.accountId = '414351767826' group by 1,2 order by 4 desc limit 10;
- Run the query to generate a table. The resulting table shows the number of API calls and the cost of those calls.
Additional API costs are often due to checkpointing directories for streaming jobs. Databricks recommends deleting old checkpointing directories if they are no longer referenced.