Problem
You have an array of struct columns with one or more duplicate column names in a DataFrame.
If you try to create a Delta table you get a Found duplicate column(s) in the data to save: error.
Example code
You can reproduce the error with this example code.
1) The first step sets up an array with duplicate column names. The duplicate columns are identified by comments in the sample code.
%scala
// Sample json file to test to_json function
val arrayStructData = Seq(
Row("James",List(Row("Java","XX",120,"Java"),Row("Scala","XA",300,"Scala"))),
Row("Michael",List(Row("Java","XY",200,"Java"),Row("Scala","XB",500,"Scala"))),
Row("Robert",List(Row("Java","XZ",400,"Java"),Row("Scala","XC",250,"Scala")))
)
import org.apache.spark.sql.types.{StructType, StructField, StringType, IntegerType, ArrayType};
val arrayStructSchema = new StructType().add("name",StringType)
.add("booksIntersted",ArrayType(new StructType()
.add("name",StringType) // Duplicate column
.add("author",StringType)
.add("pages",IntegerType)
.add("Name",StringType))) // Duplicate column
val df = spark.createDataFrame(spark.sparkContext
.parallelize(arrayStructData),arrayStructSchema)
df.printSchema // df with struct type 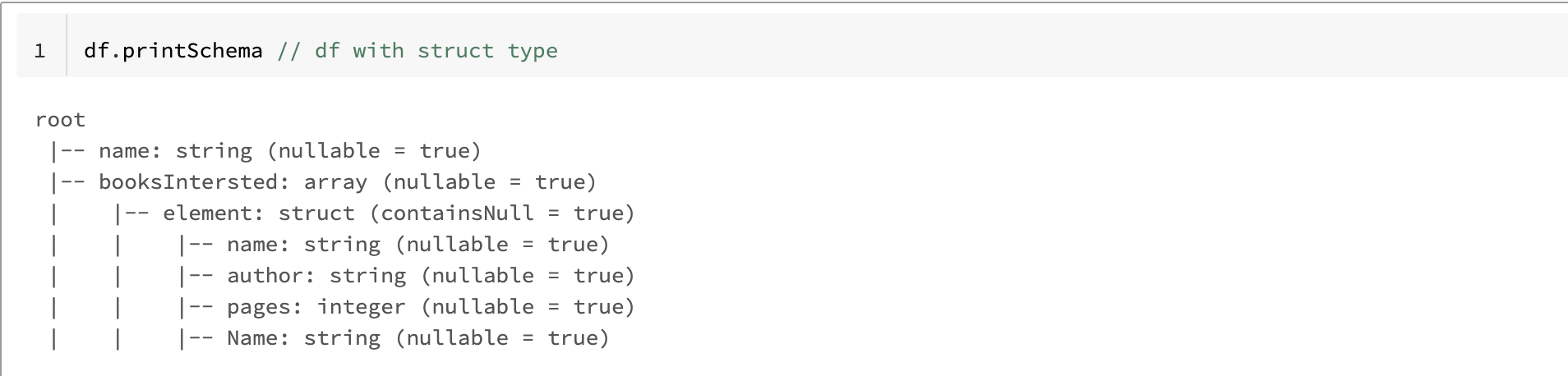
2) After validating the DataFrame, we try to create a Delta table and get the Found duplicate column(s) in the data to save: error.
%scala
df.createOrReplaceTempView("df")
df.write.format("delta").save("/mnt/delta/test/df_issue")
spark.sql("create table events using delta location '/mnt/delta/test/df_issue'")
Cause
An array of struct columns containing duplicate columns with the same name cannot be present in a Delta table. This is true even if the names are in different cases.
Delta Lake is case-preserving, but case-insensitive, when storing a schema.
In order to avoid potential data corruption or data loss, duplicate column names are not allowed.
Solution
This approach involves converting the parent column which has duplicate column names to a json string.
1) You need to convert the structtype columns to string using the to_json() function before creating the Delta table.
%scala
import org.apache.spark.sql.functions.to_json
val df1 = df.select(df("name"), to_json(df("booksIntersted")).alias("booksIntersted_string")) // Use this
df1.write.format("delta").save("/mnt/delta/df1_solution")
spark.sql("create table events_solution using delta location '/mnt/delta/df1_solution'")
spark.sql("describe events_solution").show()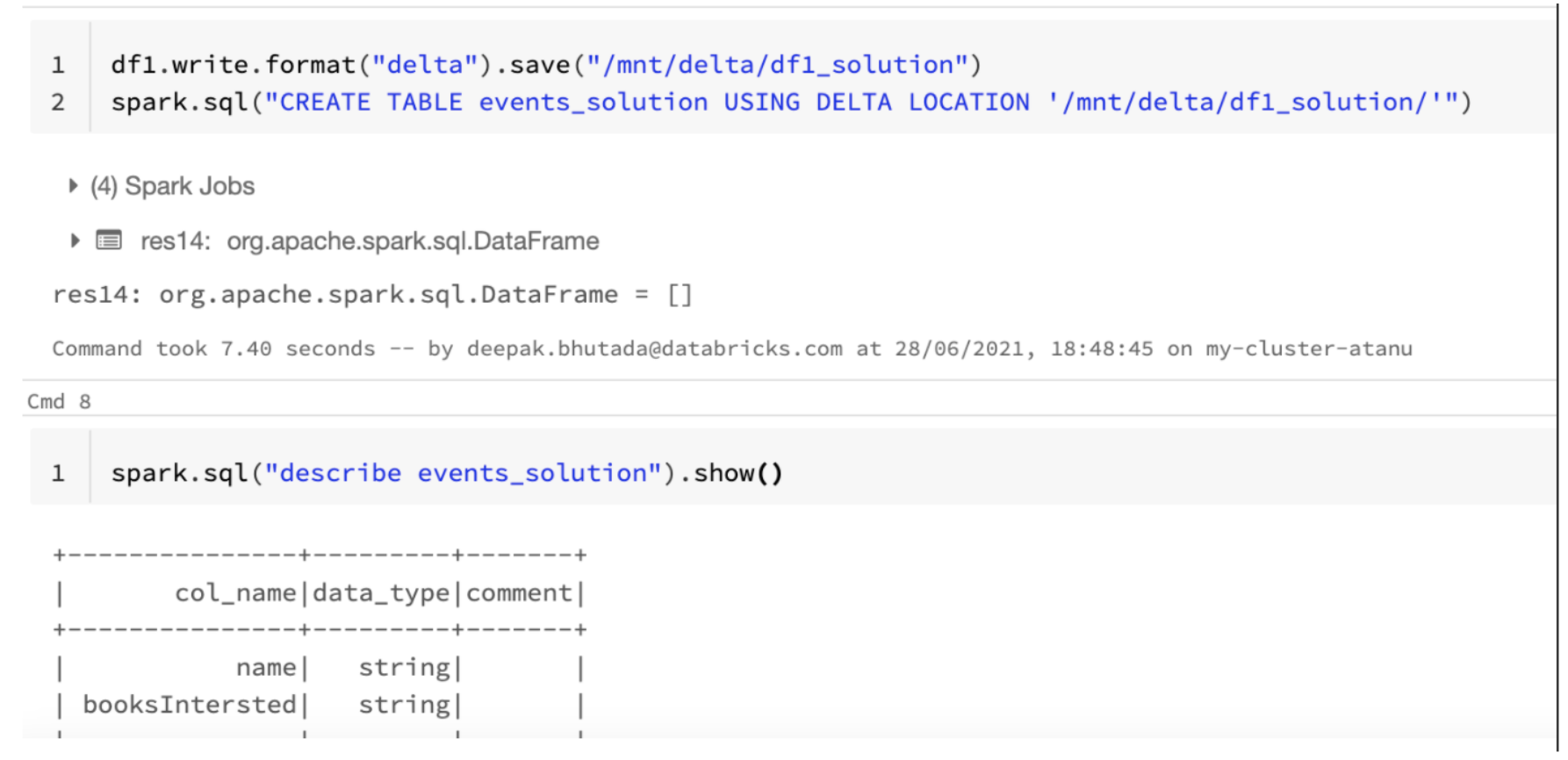
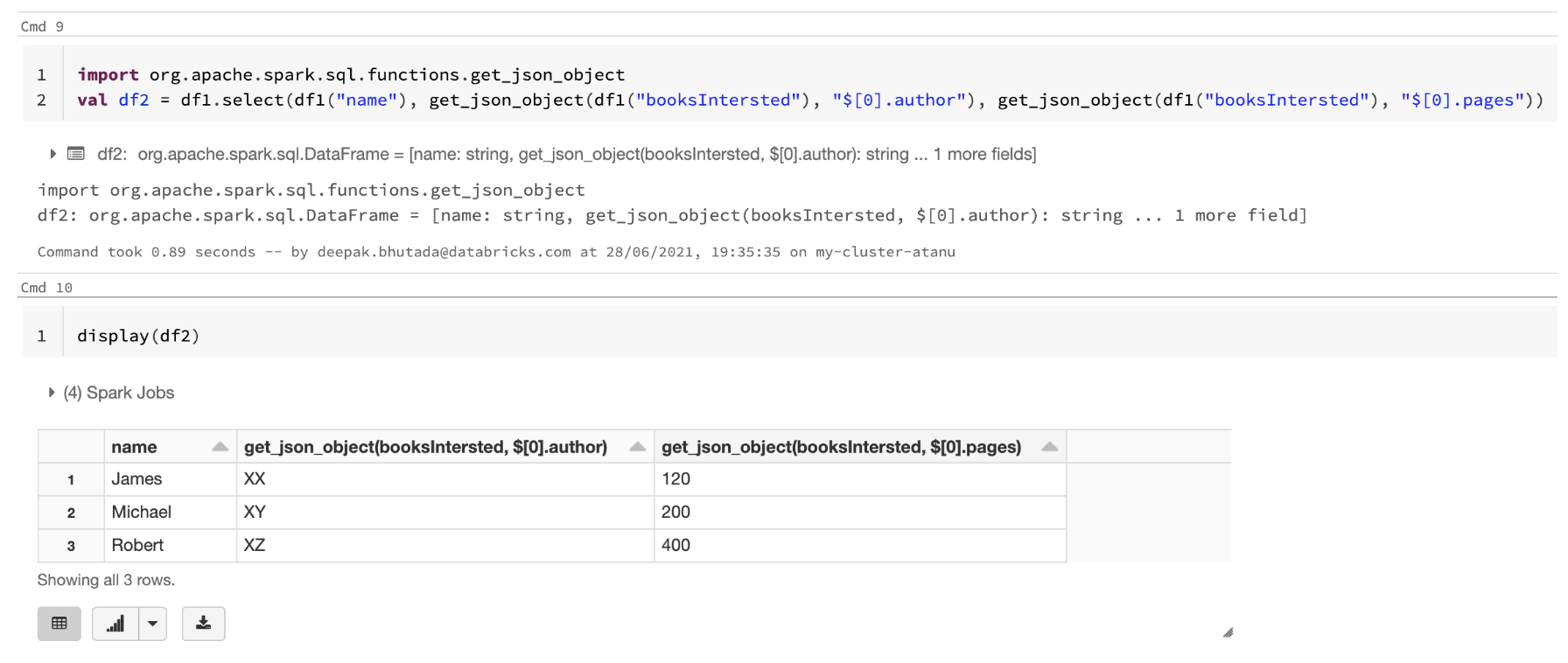
2) Use the get_json_object() function to extract information from the converted string type column.
%scala
import org.apache.spark.sql.functions.get_json_object
val df2 = df1.select(df1("name"), get_json_object(df1("bookInterested"), "${0}.author"), get_json_object(df1("bookInterested"), "${0}.pages"))
display(df2)