
Problem
If you save data containing both empty strings and null values in a column on which the table is partitioned, both values become null after writing and reading the table.
To illustrate this, create a simple DataFrame:
%scala
import org.apache.spark.sql.types._
import org.apache.spark.sql.catalyst.encoders.RowEncoder
val data = Seq(Row(1, ""), Row(2, ""), Row(3, ""), Row(4, "hello"), Row(5, null))
val schema = new StructType().add("a", IntegerType).add("b", StringType)
val df = spark.createDataFrame(spark.sparkContext.parallelize(data), schema)At this point, if you display the contents of df, it appears unchanged:

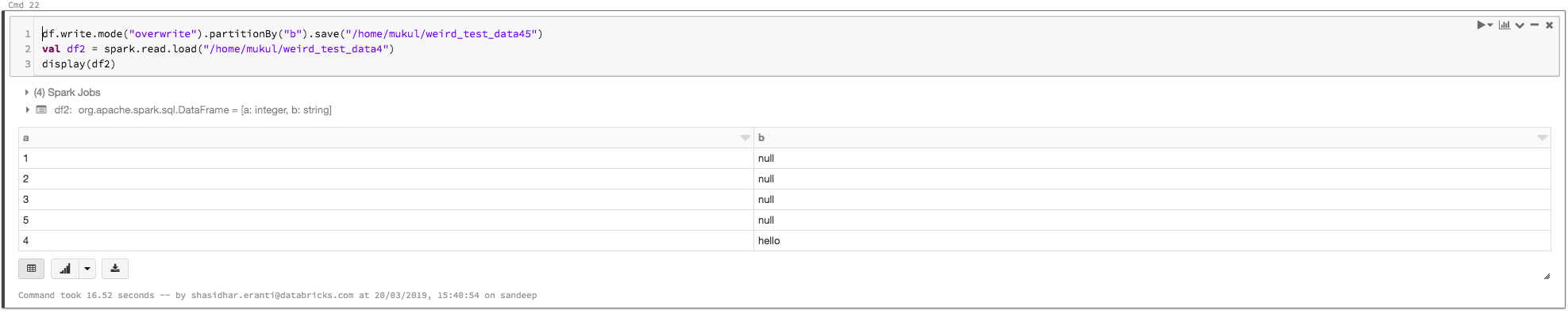
Write df, read it again, and display it. The empty strings are replaced by null values:
Cause
This is the expected behavior. It is inherited from Apache Hive.
Solution
In general, you shouldn’t use both null and empty strings as values in a partitioned column.