
Problem
Your tasks are running slower than expected.
You review the stage details in the Spark UI on your cluster and see that task deserialization time is high.
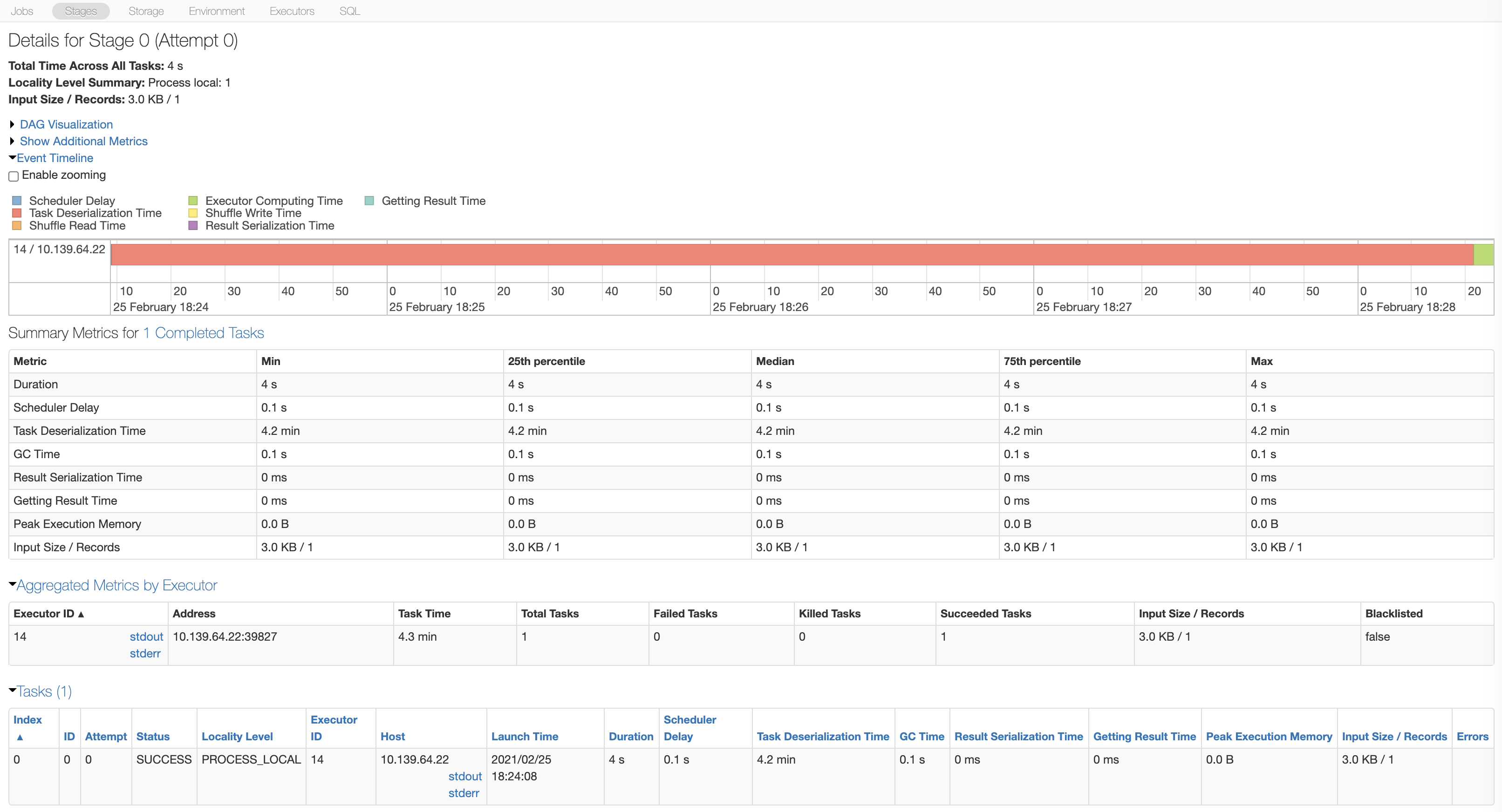
Cause
Cluster-installed libraries (AWS | Azure | GCP) are only installed on the driver when the cluster is started. These libraries are only installed on the executors when the first tasks are submitted. The time taken to install the PyPI libraries is included in the task deserialization time.
Solution
If you are using a large number of PyPI libraries, you should configure your cluster to install the libraries on all the executors when the cluster is started. This results in a slight increase to the cluster launch time, but allows your job tasks to run faster because you don’t have to wait for libraries to install on the executors after the initial launch.
Add spark.databricks.libraries.enableSparkPyPI false to the cluster’s Spark config (AWS | Azure | GCP) and restart the cluster.