
This article explains how to set up Apache Kafka on AWS EC2 machines and connect them with Databricks. Following are the high level steps that are required to create a Kafka cluster and connect from Databricks notebooks.
Table of Contents
Step 1: Create a new VPC in AWSStep 2: Launch the EC2 instance in the new VPCStep 3: Install Kafka and ZooKeeper on the new EC2 instanceStep 4: Peer two VPCsStep 5: Access the Kafka broker from a notebookStep 1: Create a new VPC in AWS
- When creating the new VPC, set the new VPC CIDR range different than the Databricks VPC CIDR range. For example:
- Databricks VPC vpc-7f4c0d18 has CIDR IP range 10.205.0.0/16.
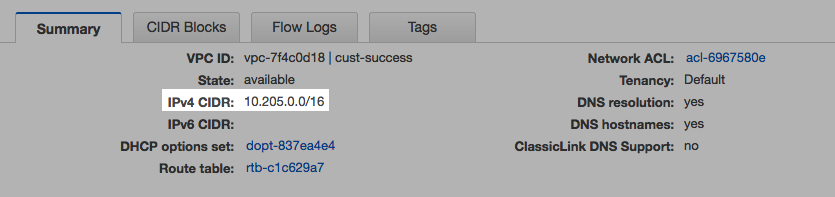
- New VPC vpc-8eb1faf7 has CIDR IP range 10.10.0.0/16.
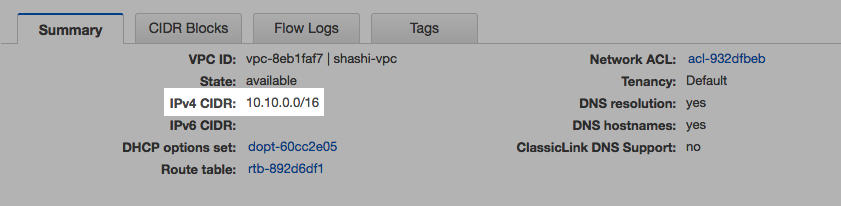
- Databricks VPC vpc-7f4c0d18 has CIDR IP range 10.205.0.0/16.
- Create a new internet gateway and attach it to the route table of the new VPC. This allows you to ssh into the EC2 machines that you launch under this VPC.
- Create a new internet gateway.
- Attach it to VPC vpc-8eb1faf7.
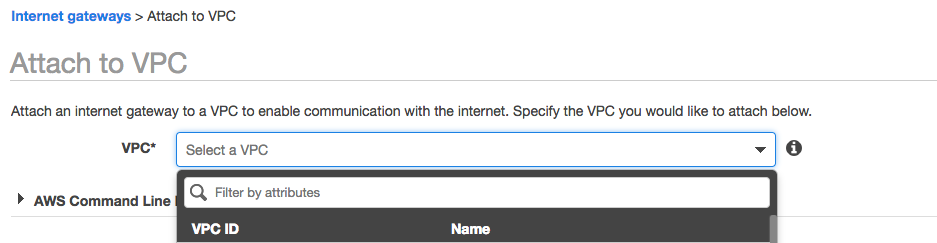
- Create a new internet gateway.
Step 2: Launch the EC2 instance in the new VPC
Launch the EC2 instance inside the new VPC vpc-8eb1faf7 created in Step 1.

Step 3: Install Kafka and ZooKeeper on the new EC2 instance
- SSH into the machine with the key pair.
ssh -i keypair.pem ec2-user@ec2-xx-xxx-xx-xxx.us-west-2.compute.amazonaws.com
- Download Kafka and extract the archive.
wget https://apache.claz.org/kafka/0.10.2.1/kafka_2.12-0.10.2.1.tgz tar -zxf kafka_2.12-0.10.2.1.tgz
- Start the ZooKeeper process.
cd kafka_2.12-0.10.2.1 bin/zookeeper-server-start.sh config/zookeeper.properties
- Edit the config/server.properties file and set 10.10.143.166as the private IP of the EC2 node.
advertised.listeners=PLAINTEXT:/10.10.143.166:9092
- Start the Kafka broker.
cd kafka_2.12-0.10.2.1 bin/kafka-server-start.sh config/server.properties
Step 4: Peer two VPCs
- Create a new peering connection.
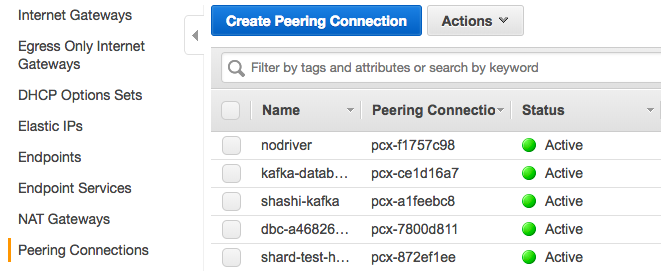
- Add the peering connection into the route tables of your Databricks VPC and new Kafka VPC created in Step 1.
- In the Kafka VPC, go to the route table and add the route to the Databricks VPC.
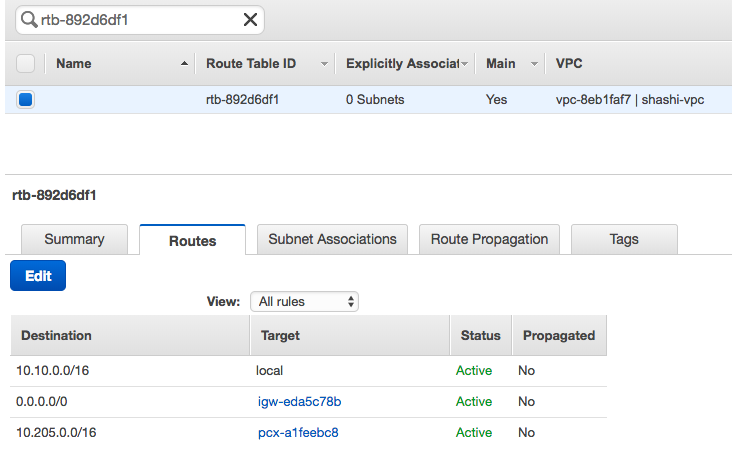
- In the Databricks VPC, go to the route table and add the route to the Kafka VPC.
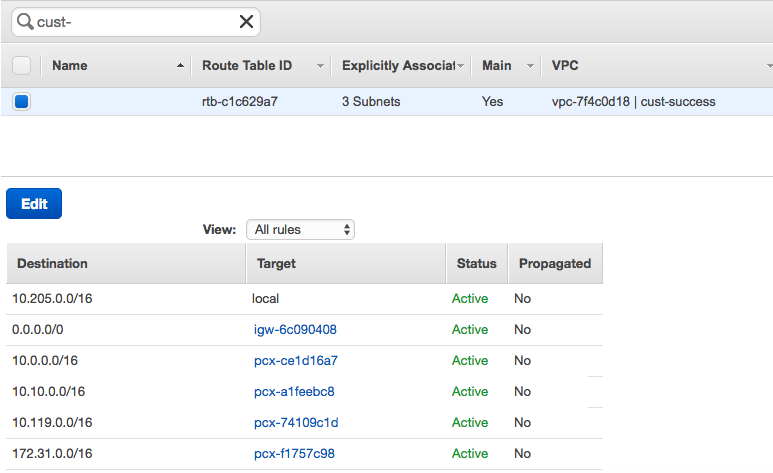
- In the Kafka VPC, go to the route table and add the route to the Databricks VPC.
For more information, see VPC Peering.
Step 5: Access the Kafka broker from a notebook
- Verify you can reach the EC2 instance running the Kafka broker with telnet.
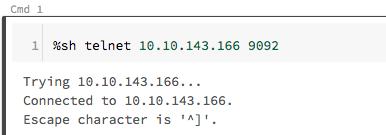
- SSH to the Kafka broker.
%sh ssh -i keypair.pem ec2-user@ec2-xx-xxx-xx-xxx.us-west-2.compute.amazonaws.com
- Create a new topic in the Kafka broker from the command line.
%sh bin/kafka-console-producer.sh --broker-list localhost:9092 --article wordcount < LICENSE
- Read data in a notebook.
%scala import org.apache.spark.sql.functions._ val kafka = spark.readStream .format("kafka") .option("kafka.bootstrap.servers", "10.10.143.166:9092") .option("subscribe", "wordcount") .option("startingOffsets", "earliest") display(kafka)