
Problem
SparkTrials is an extension of Hyperopt, which allows runs to be distributed to Spark workers.
When you start an MLflow run with nested=True in the worker function, the results are supposed to be nested under the parent run.
Sometimes the results are not correctly nested under the parent run, even though you ran SparkTrials with nested=True in the worker function.
For example:
%python
from hyperopt import fmin, tpe, hp, Trials, STATUS_OK
def train(params):
"""
An example train method that computes the square of the input.
This method will be passed to `hyperopt.fmin()`.
:param params: hyperparameters. Its structure is consistent with how search space is defined. See below.
:return: dict with fields 'loss' (scalar loss) and 'status' (success/failure status of run)
"""
with mlflow.start_run(run_name='inner_run', nested=True) as run:
x, = params
return {'loss': x ** 2, 'status': STATUS_OK}
with mlflow.start_run(run_name='outer_run_with_sparktrials'):
spark_trials_run_id = mlflow.active_run().info.run_id
argmin = fmin(
fn=train,
space=search_space,
algo=algo,
max_evals=16,
trials=spark_trials
)Expected results:
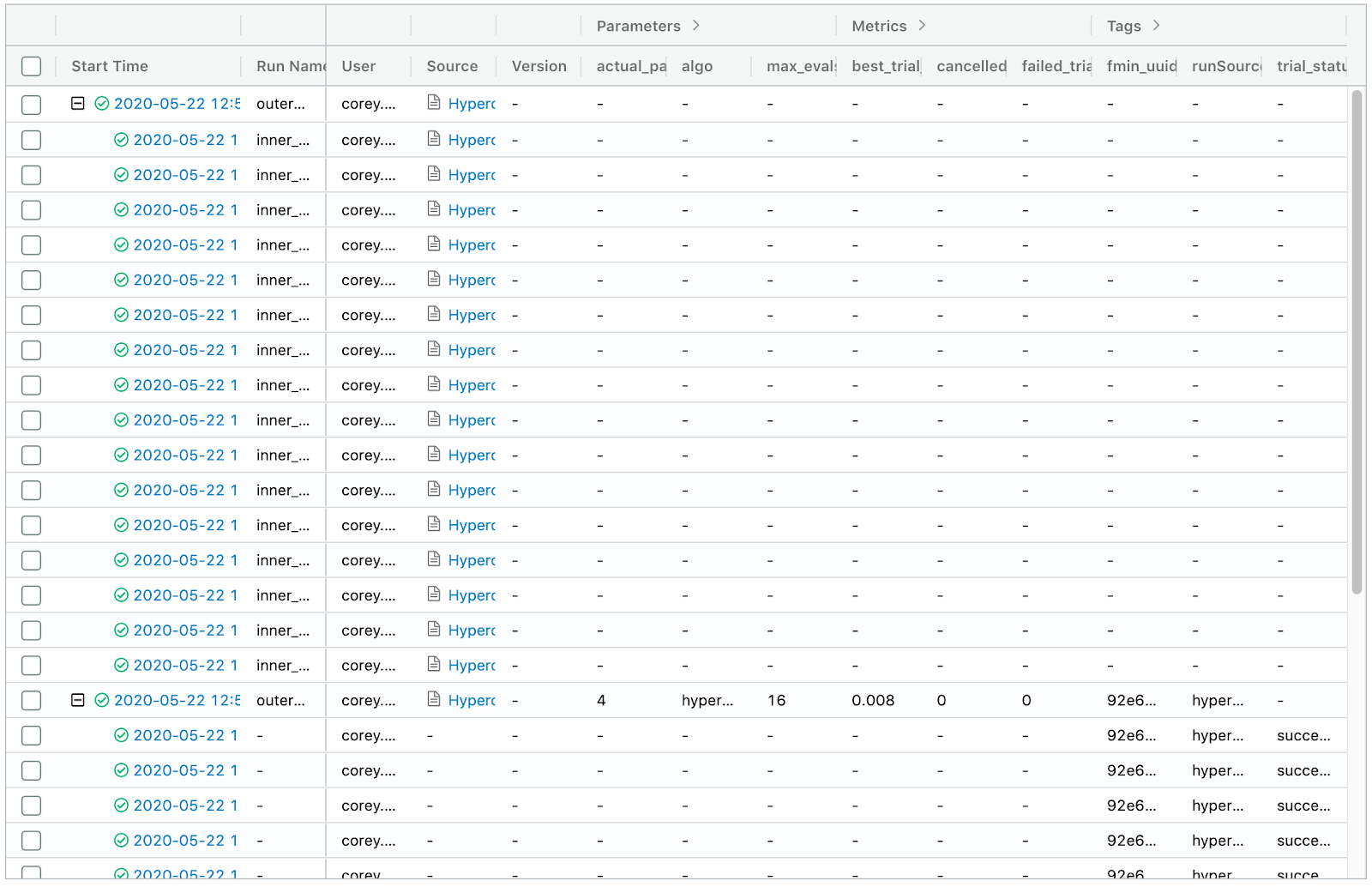
Actual results:
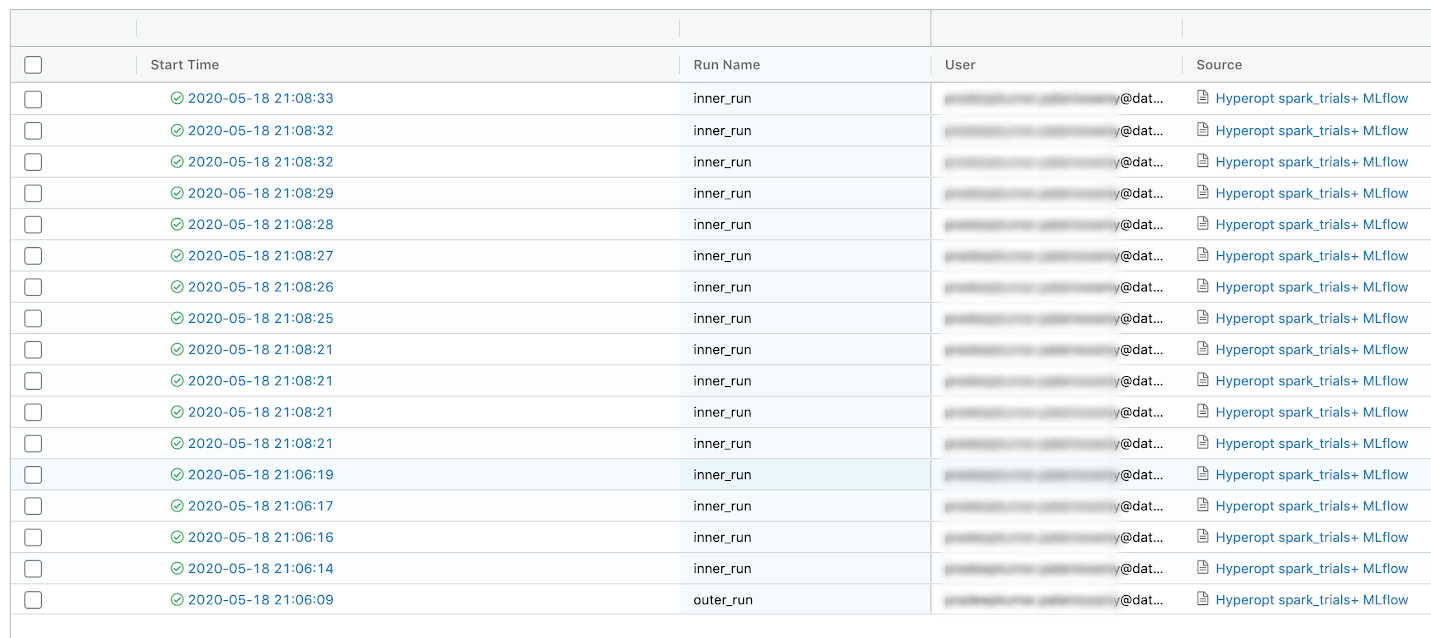
Cause
The open source version of Hyperopt does not support the required features necessary to properly nest SparkTrials MLflow runs on Databricks.
Solution
Databricks Runtime for Machine Learning includes an internal fork of Hyperopt with additional features. If you want to use SparkTrials, you should use Databricks Runtime for Machine Learning instead of installing Hyperopt manually from open-source repositories.