Problem
You are attempting to query an external Hive table, but it keeps failing to skip the header row, even though TBLPROPERTIES ('skip.header.line.count'='1') is set in the HiveContext.
You can reproduce the issue by creating a table with this sample code.
%sql CREATE EXTERNAL TABLE school_test_score ( `school` varchar(254), `student_id` varchar(254), `gender` varchar(254), `pretest` varchar(254), `posttest` varchar(254)) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION 'dbfs:/FileStore/table_header/' TBLPROPERTIES ( 'skip.header.line.count'='1' )
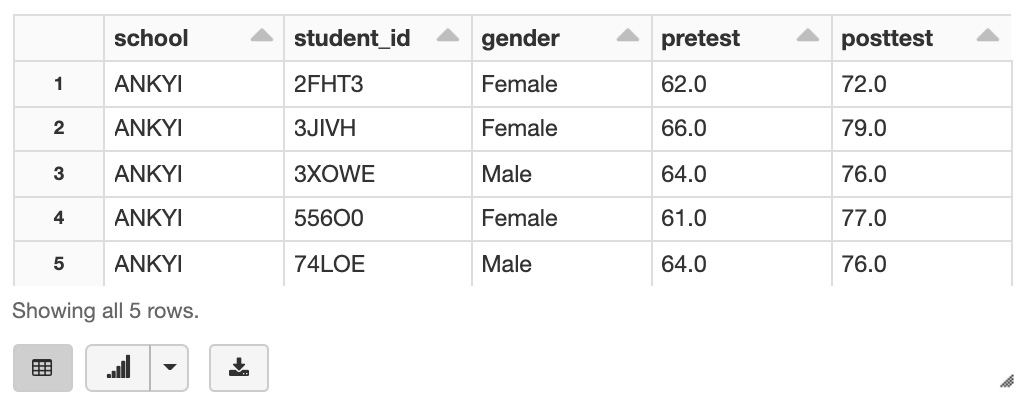
If you try to select the first five rows from the table, the first row is the header row.
%sql SELECT * FROM school_test_score LIMIT 5
Cause
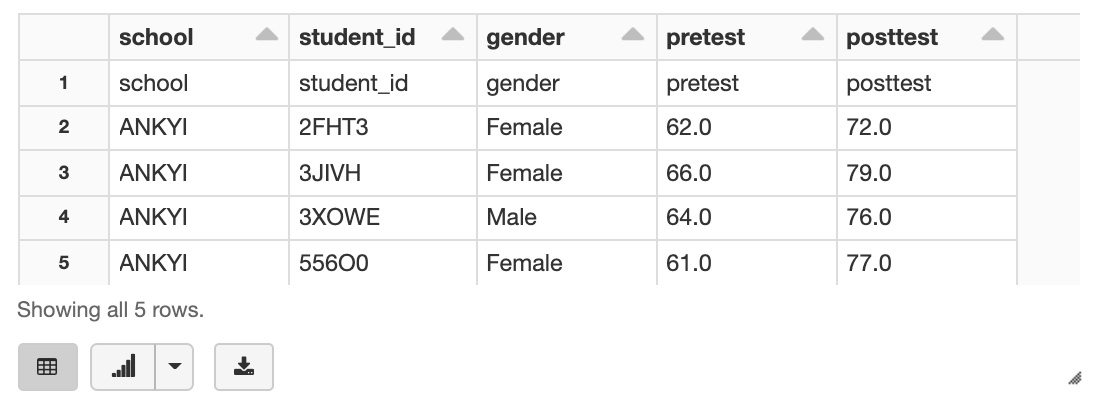
If you query directly from Hive, the header row is correctly skipped. Apache Spark does not recognize the skip.header.line.count property in HiveContext, so it does not skip the header row.
Spark is behaving as designed.
Solution
You need to use Spark options to create the table with a header option.
%sql CREATE TABLE student_test_score (school String, student_id String, gender String, pretest String, posttest String) USING CSV OPTIONS (path "dbfs:/FileStore/table_header/", delimiter ",", header "true") ;
Select the first five rows from the table and the header row is not included.
%sql SELECT * FROM school_test_score LIMIT 5