When you stream data into a file sink, you should always change both checkpoint and output directories together. Otherwise, you can get failures or unexpected outputs.
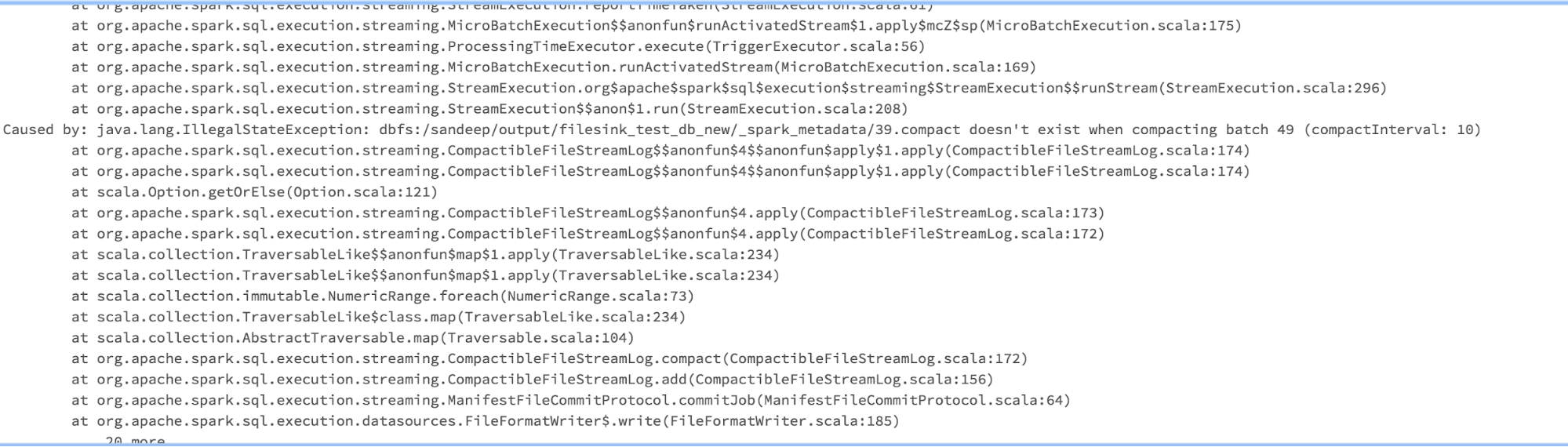
Apache Spark creates a folder inside the output directory named _spark_metadata. This folder contains write-ahead logs for every batch run. This is how Spark gets exactly-once guarantees when writing to a file system. This folder contains save files for each batch (named 0,1,2,3 etc + 19.compact, n.compact etc). These files include JSON that gives details about the output for the particular batch. With the help of this data, once a batch has succeeded, any duplicate batch output is discarded.
If you change the checkpoint directory but not the output directory:
When you change the checkpoint directory, the stream job will start batches again from 0. Since 0 is already present in the _spark_metadata folder, the output file will be discarded even if it has new data. That is, if you stop the previous run on the 500th batch, the next run with same output directory and different checkpoint directory will give output only on the 501st batch. All of the previous batches will be silently discarded.
If you change the output directory but not the checkpoint directory:
When you change only the output directory, it loses all of the batch data from the _spark_metadata folder. But Spark starts writing from the next batch according to the checkpoint directory. For example, if the previous run was stopped at 500, the first write of the new stream job will be at file 501 on _spark_metadata and you lose all of the old batches. When you read the files back, you get the error metadata for batch 0(or first compact file (19.compact)) is not found.