
When you create a cluster, Databricks launches one Apache Spark executor instance per worker node, and the executor uses all of the cores on the node. In certain situations, such as if you want to run non-thread-safe JNI libraries, you might need an executor that has only one core or task slot, and does not attempt to run concurrent tasks. In this case, multiple executor instances run on a single worker node, and each executor has only one core.
If you run multiple executors, you increase the JVM overhead and decrease the overall memory available for processing.
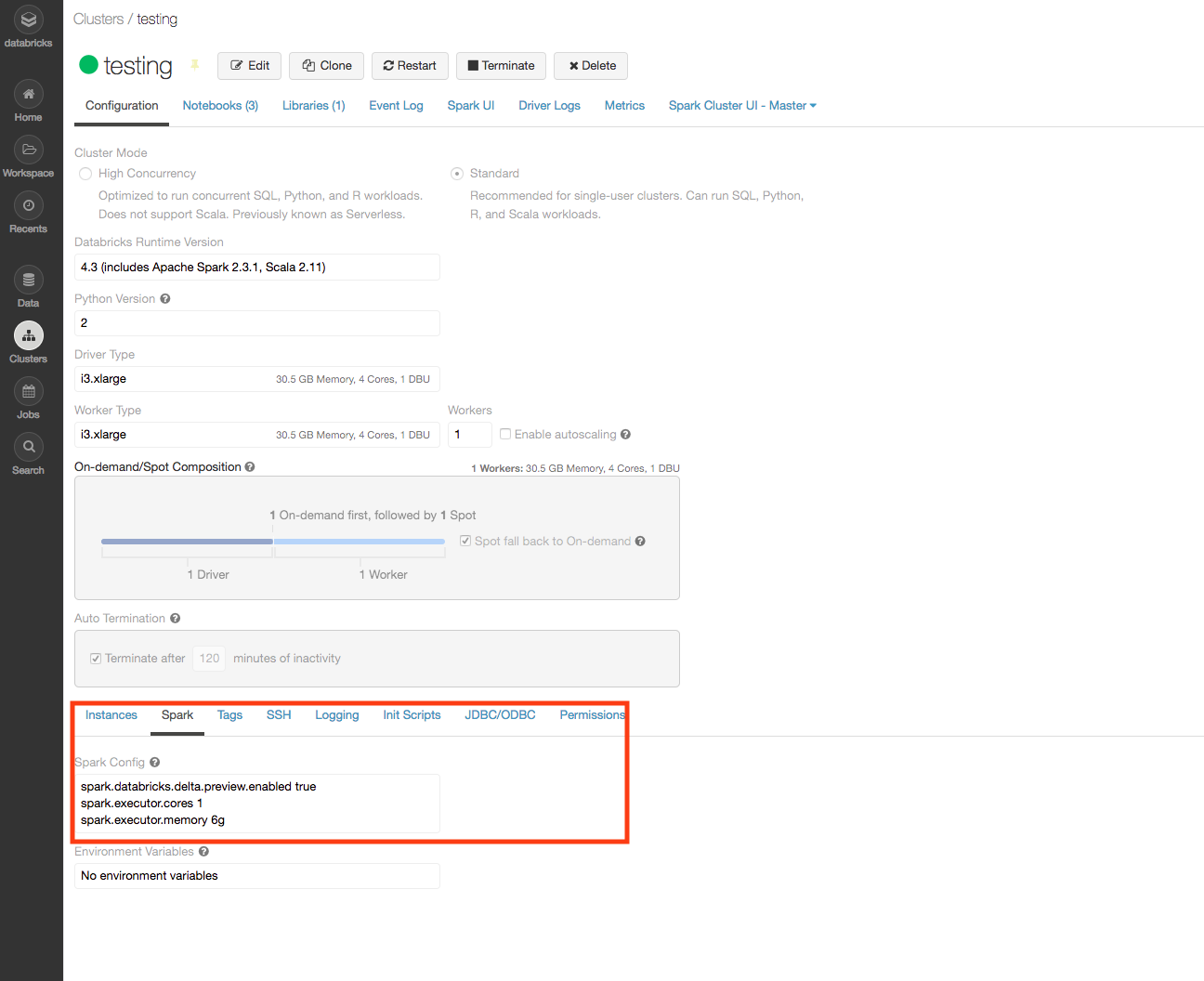
To start single-core executors on a worker node, configure two properties in the Spark Config:
- spark.executor.cores
- spark.executor.memory
The property spark.executor.cores specifies the number of cores per executor. Set this property to 1.
The property spark.executor.memory specifies the amount of memory to allot to each executor. This must be set high enough for the executors to properly function, but low enough to allow for all cores to be used.
AWS
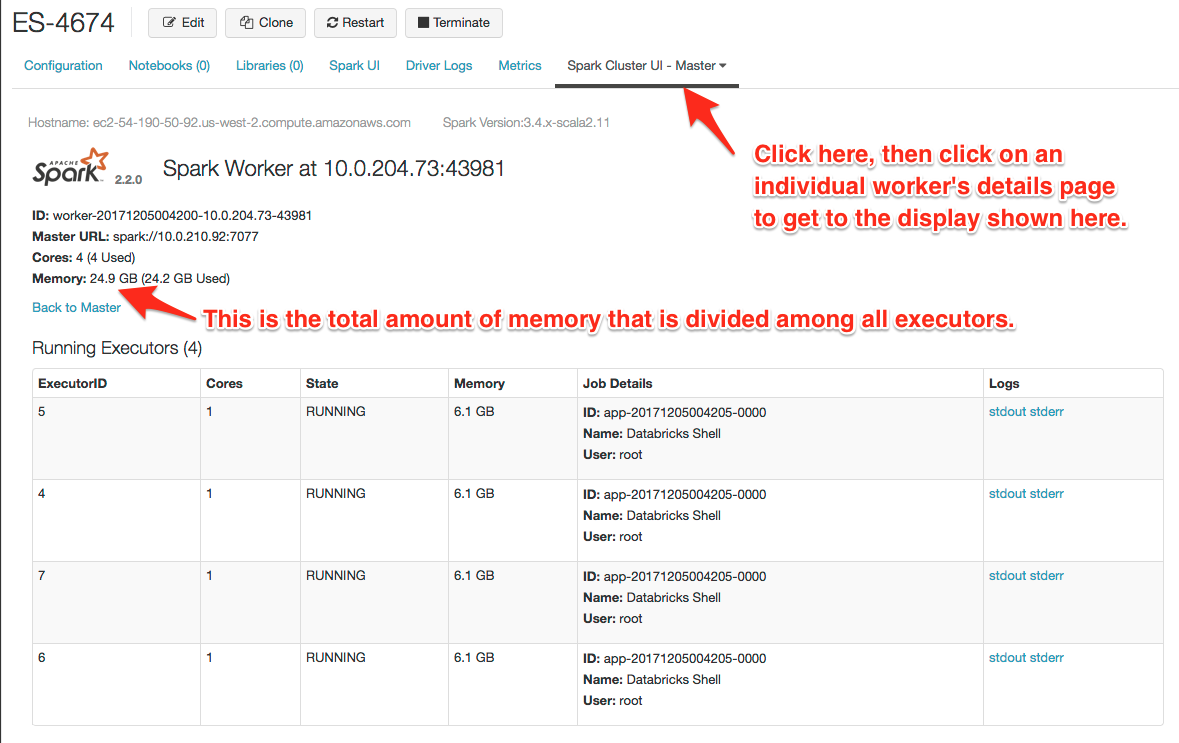
For example, an i3.xlarge node, which has 30.5 GB of memory, shows available memory at 24.9 GB. Choose a value that fits the available memory when multiplied by the number of executors. You may need to set a value that allows for some overhead. For example, set spark.executor.cores to 1 and spark.executor.memory to 6g:
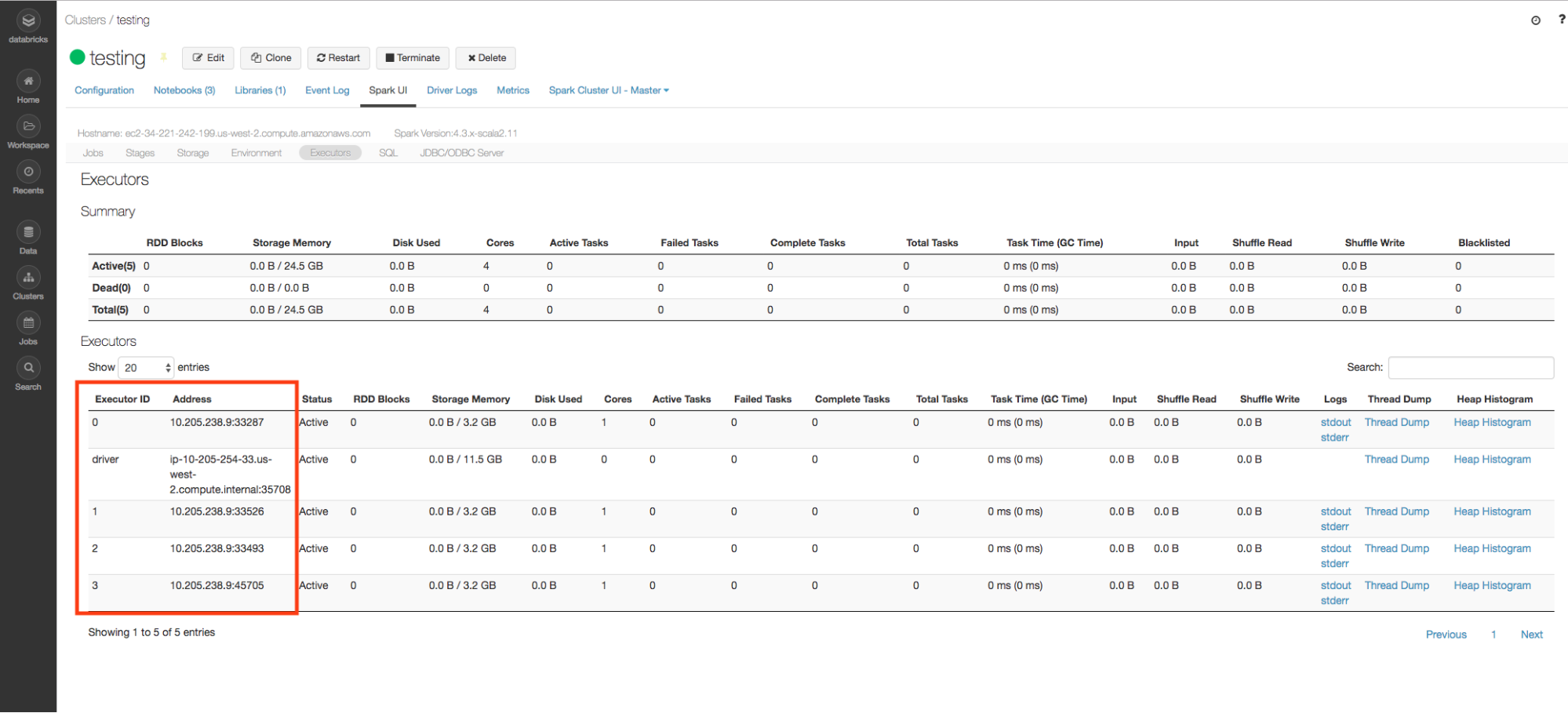
The i3.xlarge instance type has 4 cores, and so 4 executors are created on the node, each with 6 GB of memory.
GCP
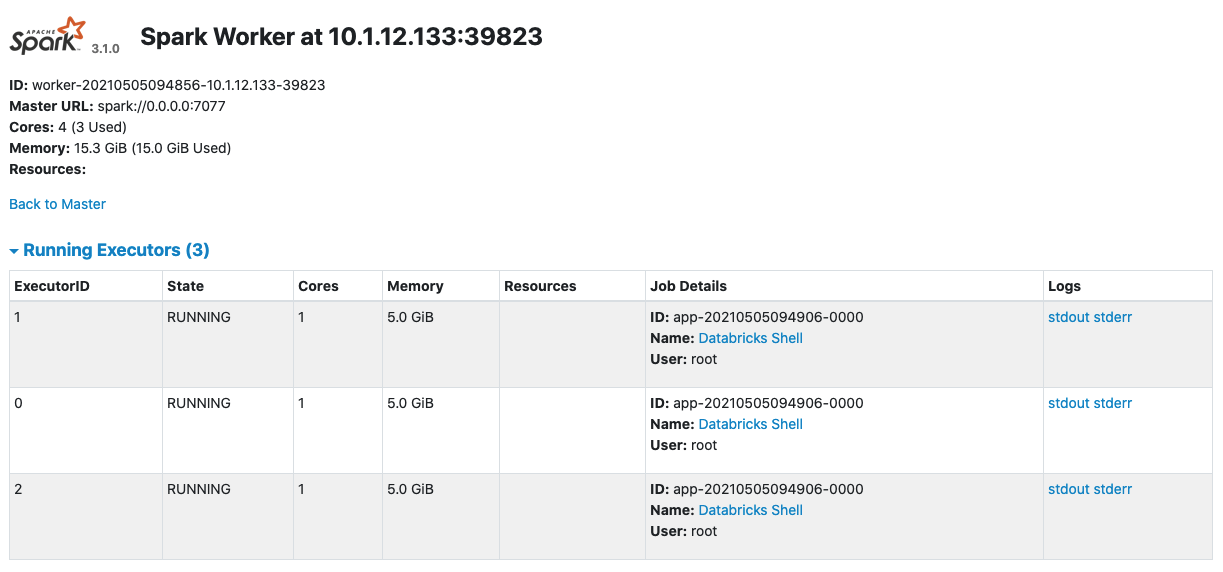
For example, the n1-highmem-4 worker node has 26 GB of total memory, but only has 15.3 GB of available memory once the cluster is running.
Using an example Spark Config value, we set the core value to 1 and assign 5 GB of memory to each executor.
spark.executor.cores 1 spark.executor.memory 5g
Once the cluster starts, the worker nodes each have 4 cores, but only 3 are used. There are 3 executors, each with 5 GB of memory on each worker node. This is a total of 15 GB of memory used.
The fourth core never spins up, as there is not enough memory to allocate to it.
You must balance your choice of instance type with the memory required by each executor in order to maximize the use of every core on your worker nodes.
Delete