
Apache Spark does not include a streaming API for XML files. However, you can combine the auto-loader features of the Spark batch API with the OSS library, Spark-XML, to stream XML files.
In this article, we present a Scala based solution that parses XML data using an auto-loader.
Install Spark-XML library
You must install the Spark-XML OSS library on your Databricks cluster.
Review the install a library on a cluster (AWS | Azure) documentation for more details.
Create the XML file
Create the XML file and use DBUtils (AWS | Azure) to save it to your cluster.
%scala
val xml2="""<people>
<person>
<age born="1990-02-24">25</age>
</person>
<person>
<age born="1985-01-01">30</age>
</person>
<person>
<age born="1980-01-01">30</age>
</person>
</people>"""
dbutils.fs.put("/<path-to-save-xml-file>/<name-of-file>.xml",xml2)Define imports
Import the required functions.
%scala
import com.databricks.spark.xml.functions.from_xml
import com.databricks.spark.xml.schema_of_xml
import spark.implicits._
import com.databricks.spark.xml._
import org.apache.spark.sql.functions.{<input_file_name>}Define a UDF to convert binary to string
The streaming DataFrame requires data to be in string format.
You should define a user defined function to convert binary data to string data.
%scala val toStrUDF = udf((bytes: Array[Byte]) => new String(bytes, "UTF-8"))
Extract XML schema
You must extract the XML schema before you can implement the streaming DataFrame.
This can be inferred from the file using the schema_of_xml method from Spark-XML.
The XML string is passed as input, from the binary Spark data.
%scala
val df_schema = spark.read.format("binaryFile").load("/FileStore/tables/test/xml/data/age/").select(toStrUDF($"content").alias("text"))
val payloadSchema = schema_of_xml(df_schema.select("text").as[String])Implement the stream reader
At this point, all of the required dependencies have been met, so you can implement the stream reader.
Use readStream with binary and autoLoader listing mode options enabled.
toStrUDF is used to convert binary data to string format (text).
from_xml is used to convert the string to a complex struct type, with the user-defined schema.
%scala
val df = spark.readStream.format("cloudFiles")
.option("cloudFiles.useNotifications", "false") // Using listing mode, hence false is used
.option("cloudFiles.format", "binaryFile")
.load("/FileStore/tables/test/xml/data/age/")
.select(toStrUDF($"content").alias("text")) // UDF to convert the binary to string
.select(from_xml($"text", payloadSchema).alias("parsed")) // Function to convert string to complex types
.withColumn("path",input_file_name) // input_file_name is used to extract the paths of input filesView output
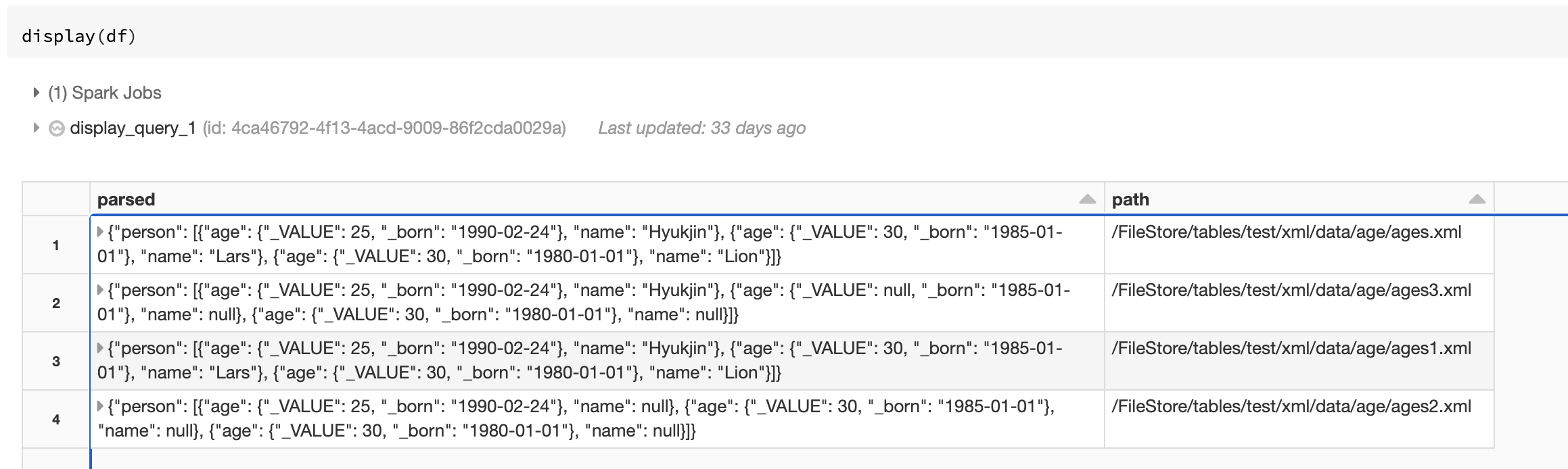
Once everything is setup, view the output of display(df) in a notebook.
Example notebook
This example notebook combines all of the steps into a single, functioning example.
Import it into your cluster to run the examples.
Streaming XML example notebook
Review the Streaming XML example notebook.