When using the spark-xml package, you can increase the number of tasks per stage by changing the configuration setting spark.hadoop.mapred.max.split.size to a lower value in the cluster’s Spark config (AWS | Azure). This configuration setting controls the input block size. When data is read from DBFS, it is divided into input blocks, which are then sent to different executors. This configuration controls the size of these input blocks. By default, it is 128 MB (128000000 bytes).
Setting this value in the notebook with spark.conf.set() is not effective.
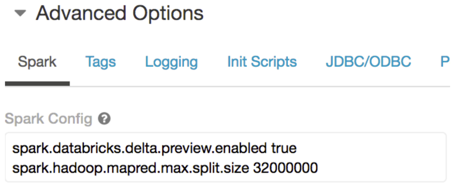
In the following example, the Spark config field shows that the input block size is 32 MB.