Problem
If data in S3 is stored by partition, the partition column values are used to name folders in the source directory structure. However, if you use an SQS queue as a streaming source, the S3-SQS source cannot detect the partition column values.
For example, if you save the following DataFrame to S3 in JSON format:
%scala
val df = spark.range(10).withColumn("date",current_date())
df.write.partitionBy("date").json("s3a://bucket-name/json")The file structure underneath will be:
%scala s3a://bucket-name/json/_SUCCESS s3a://bucket-name/json/date=2018-10-25/<individual JSON files>
Let’s say you have an S3-SQS input stream created from the queue configured for this S3 bucket. If you directly load the data from this S3-SQS input stream using the following code:
%scala
import org.apache.spark.sql.types._
val schema = StructType(List(StructField("id", IntegerType, false),StructField("date", DateType, false)))
display(spark.readStream
.format("s3-sqs")
.option("fileFormat", "json")
.option("queueUrl", "https://sqs.us-east-1.amazonaws.com/826763667205/sqs-queue")
.option("sqsFetchInterval", "1m")
.option("ignoreFileDeletion", true)
.schema(schema)
.load())The output will be:
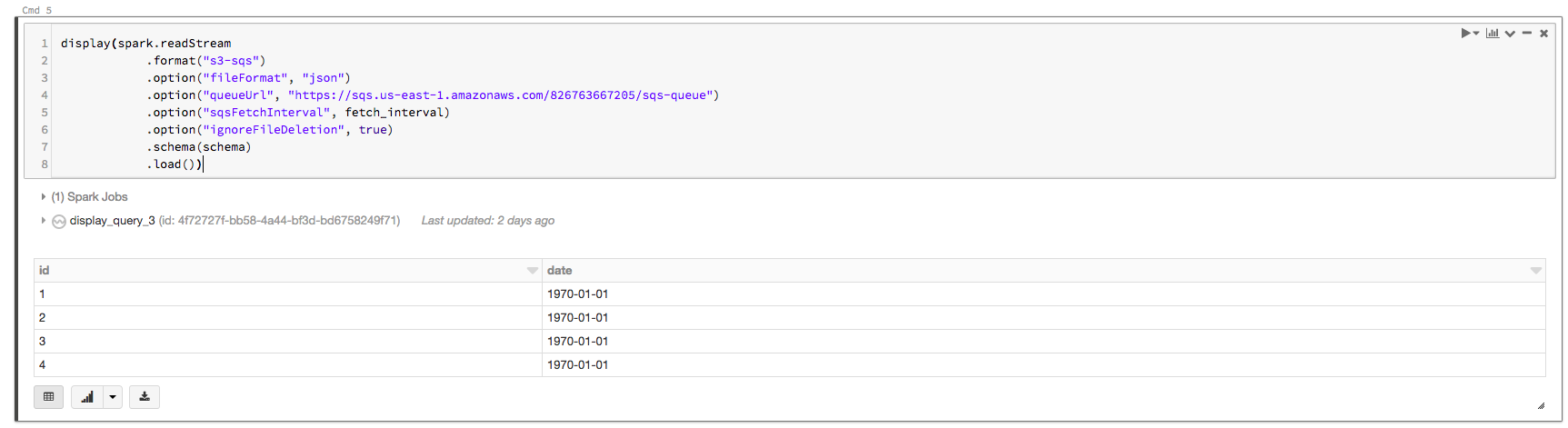
You can see the date column values are not populated correctly.
Solution
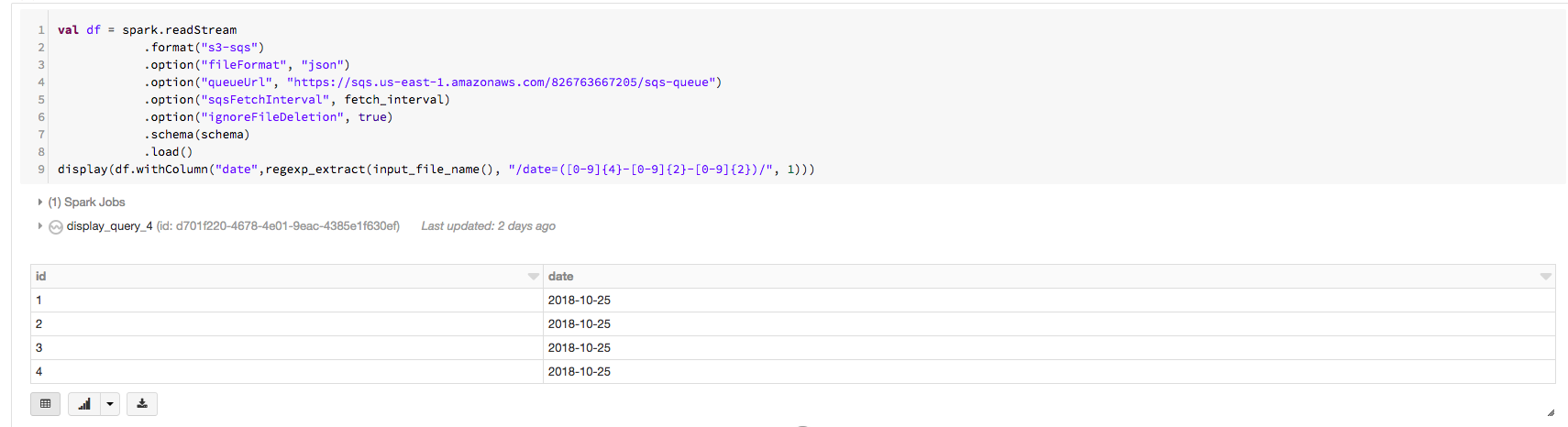
You can use a combination of input_file_name() and regexp_extract() UDFs to extract the date values properly, as in the following code snippet:
%scala
import org.apache.spark.sql.functions._
val df = spark.readStream
.format("s3-sqs")
.option("fileFormat", "json")
.option("queueUrl", "https://sqs.us-east-1.amazonaws.com/826763667205/sqs-queue")
.option("sqsFetchInterval", fetch_interval)
.option("ignoreFileDeletion", true)
.schema(schema)
.load()
display(df.withColumn("date",regexp_extract(input_file_name(), "/date=(\\d{4}-\\d{2}-\\d{2})/", 1)))Now you can see the correct values for the date column in the following output: